
 by
by Index
NLP (Natural Language Processing) yes but with what?
As promised! I told you in my article on the bag of words that we would go further with NLP, and here we are. Now, which tool to choose? which library to use? indeed the Python world seems to be torn between two packages : the historic NLTK (Natural Language Toolkit) and the new little SpaCy (2015) .
Far from me the idea of making a comparison of these two very good libraries which are NLTKand SpaCy . There are pros and cons with each, but the ease of use, the availability of pre-trained word vectors as well as statistical models in several languages (English, German and Spanish) but especially in French definitely have me. switches to SpaCy. Make way for young people.
This little tutorial will therefore show you how to use this library.
Install and use the library
This library is not installed by default with Python. The easiest way to install it is to run a command line and use the pip utility as follows:
pip install -U spaCy
python -m spacy download fr
python -m spacy download fr_core_news_md
NB: The last two commands allow you to use models already trained in French. Then to use SpaCy you have to import the library but also initialize it with the right language with the load () directive
import spacy
from spacy import displacy
nlp = spacy.load('fr')
Tokenization
The first thing we are going to do is to “tokenize” a sentence in order to cut it grammatically. Tokenization is the operation of segmenting a sentence into “atomic” units: tokens. The most common tokenizations are splitting into words or sentences. We will start with the words and for that we will use the token class of SpaCy:
import spacy
from spacy import displacy
nlp = spacy.load('fr')
doc = nlp('Demain je travaille à la maison')
for token in doc:
print(token.text)
The previous code cuts out the sentence ‘Tomorrow I work at home’ and displays each item
Demain
je
travaille
à
la
maison
en
FranceNothing very impressive so far, we just cut out a sentence. Now let’s take a closer look at what SpaCy did in addition to this slicing:
doc = nlp("Demain je travaille à la maison.")
for token in doc:
print("{0}\t{1}\t{2}\t{3}\t{4}\t{5}\t{6}\t{7}\t{8}".format(
token.text,
token.idx,
token.lemma_,
token.is_punct,
token.is_space,
token.shape_,
token.pos_,
token.tag_,
token.ent_type_
))
The token object is much richer than it looks and returns a lot of grammatical information about the words in the sentence:
Demain 0 Demain False False Xxxxx PROPN PROPN___
je 7 il False False xx PRON PRON__Number=Sing|Person=1
travaille 10 travailler False False xxxx VERB VERB__Mood=Ind|Number=Sing|Person=1|Tense=Pres|VerbForm=Fin
à 20 à False False x ADP ADP___
la 22 le False False xx DET DET__Definite=Def|Gender=Fem|Number=Sing|PronType=Art
maison 25 maison False False xxxx NOUN NOUN__Gender=Fem|Number=Sing
. 31 . True False . PUNCT PUNCT___ This object informs us of the use / qualification of each word (for more details go to SpaCy help ):
- text: The original text / word
- lemma_: the basic form of the word (for a conjugated verb for example we will have its infinitive)
- pos_: The part-of-speech tag (details here )
- tag_: The detailed part-of-speech information (detail here )
- dep_: Syntax dependency (inter-token)
- shape: format / pattern
- is_alpha: Alphanumeric?
- is_stop: Is the word part of a Stop-List?
- etc.
Tokenison now sentences. In fact, the work is already done (Cf. documentation ) and you just have to retrieve the sents object from the document:
doc = nlp("Demain je travaille à la maison. Je vais pouvoir faire du NLP")
for sent in doc.sents:
print(sent)
The result :
Demain je travaille à la maison.
Je vais pouvoir faire du NLPSpaCy of course allows you to recover nominal sentences (ie sentences without verbs):
doc = nlp("Terrible désillusion pour la championne du monde")
for chunk in doc.noun_chunks:
print(chunk.text, " --> ", chunk.label_)
Terrible désillusion pour la championne du monde --> NPNER
SpaCy has a very efficient statistical entity recognition system (NER or Named Entity Recognition) which will assign labels to contiguous ranges of tokens.
doc = nlp("Demain je travaille en France chez Tableau")
for ent in doc.ents:
print(ent.text, ent.label_)
The preceding code goes through the words in their context and will recognize that France is an element of localization and that Tableau is a (commercial) organization:
France LOC
Tableau ORGDependencies
Personally I find that this is the most impressive function because thanks to it we will be able to recompose a sentence by connecting the words in their context. In the example below we take our sentence and indicate each dependency with the properties dep_
<pre class="wp-block-syntaxhighlighter-code">doc = nlp('Demain je travaille en France chez Tableau')
for token in doc:
print("{0}/{1} <--{2}-- {3}/{4}".format(
token.text,
token.tag_,
token.dep_,
token.head.text,
token.head.tag_))</pre>
The result is interesting but not really readable:
Demain/PROPN___ <--advmod-- travaille/VERB__Mood=Ind|Number=Sing|Person=1|Tense=Pres|VerbForm=Fin
je/PRON__Number=Sing|Person=1 <--nsubj-- travaille/VERB__Mood=Ind|Number=Sing|Person=1|Tense=Pres|VerbForm=Fin
travaille/VERB__Mood=Ind|Number=Sing|Person=1|Tense=Pres|VerbForm=Fin <--ROOT-- travaille/VERB__Mood=Ind|Number=Sing|Person=1|Tense=Pres|VerbForm=Fin
en/ADP___ <--case-- France/PROPN__Gender=Fem|Number=Sing
France/PROPN__Gender=Fem|Number=Sing <--obl-- travaille/VERB__Mood=Ind|Number=Sing|Person=1|Tense=Pres|VerbForm=Fin
chez/ADP___ <--case-- Tableau/NOUN__Gender=Masc|Number=Sing
Tableau/NOUN__Gender=Masc|Number=Sing <--obl-- travaille/VERB__Mood=Ind|Number=Sing|Person=1|Tense=Pres|VerbForm=FinFortunately SpaCy has a trace function to make this result visual. To use it you need to import displacy:
from spacy import displacy
displacy.render(doc, style='dep', jupyter=True, options={'distance': 130})
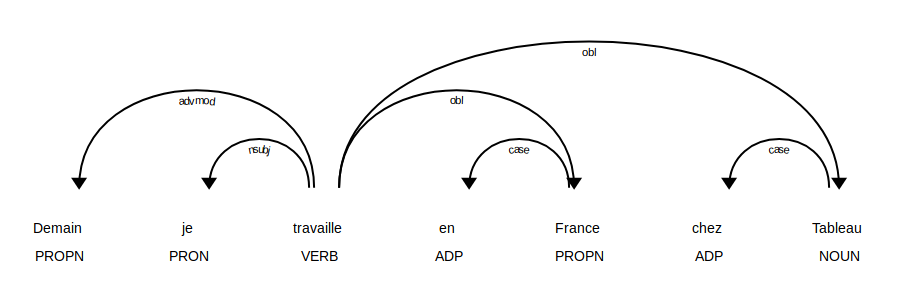
It is immediately more speaking like that right?
This concludes this first part on the use of NLP with the SpaCy library. You can find the codes for this mini-tutorial on GitHub.
For those curious about NLP, do not hesitate to read my article on NLTK as well .



One thought on “Tutorial: Just do NLP with SpaCy!”