YOLO (Part 4) Reduce detected classes
 by
by In this article we will see a trick that reduces the scope of object detection using YOLO v4.
All to understand and practice A.I. in a simple way
Image processing posts
In this article we will see a trick that reduces the scope of object detection using YOLO v4.
In my previous articles on YOLO we saw how to use this network … but when we apply this algorithm on complex images we quickly see that multiple detections are made for the same objects. We will see in this article how to remove these duplicate frames with the so-called NMS technique.
In this article we will see step by step how to use the YOLO neural network with its implementation in OpenCV. Follow the guide 😉
We will see in this article, how with the YOLO neural network we can very simply detect several objects in a photo. The objective is not to go into the details of the implementation of this neural network (much more complex than a simple sequential CNN) but rather to show how to use the implementation which was carried out in C ++ and which is called Darknet.
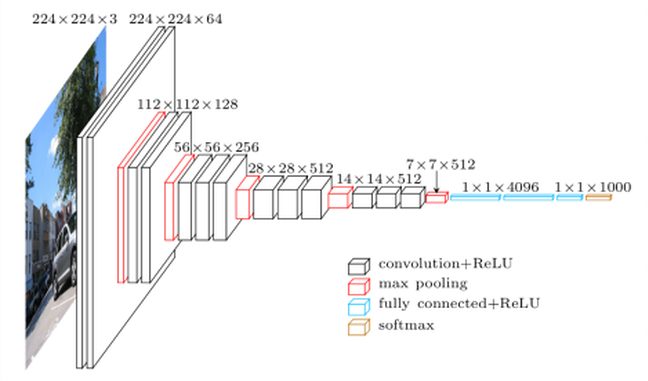
In this article we will discuss the concept of Transfer Learning … or how to avoid redoing long and consuming learning by partially reusing a pre-trained neural network. To do this we will use a network which is the reference in the matter: VGG-Net (vgg16).
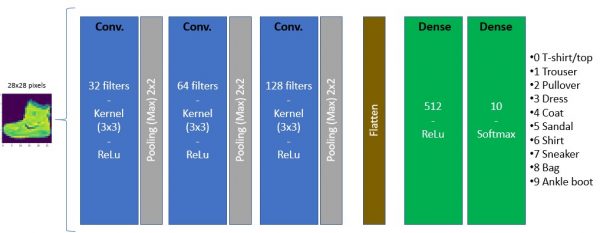
In this article we will see step by step how to create and use a convolutional neural network (CNN) to classify images.
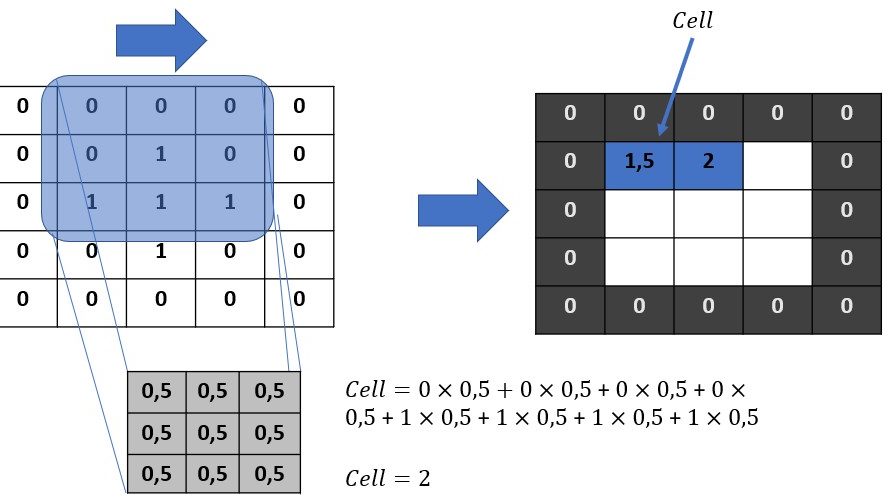
We will discuss in this post a kind of filters widely used by all images software (such as Photoshop or Gimp). In fact and to go further (without “sploiling” the following posts either) this convolution principle will also be widely used by neural networks (Deep Learning) … but we will see that later. First of all, let’s focus on the principle of these convolution filters.
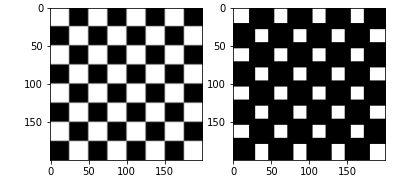
We will see in this article the principles of erosion and dilation of images which are widely used especially during the restoration of poor quality images.
We will see in this article how to perform some basic transformations on images with scikit-image such as rotating, and changing image scale and size.