
 by
by The goal of this article is to provide a quick little tutorial that will allow you to quickly and easily access your Hadoop cluster via Hive and HDFS. If you take a quick look on the internet you will see that there is a plethora of solutions and libraries for this. There is in particular a Python library called PyDev which is rather efficient … if you manage to install it correctly.
Index
PySpark
In this tutorial, we will use PySpark which as its name suggests uses the Spark framework. Remember here that Spark is not a programming language but a distributed computing environment or framework. By nature it is therefore widely used with Hadoop.
We will read and write data to hadoop. It is therefore necessary to keep in mind that Spark does not handle a file but Resilient Distributed Dataset or RDD.
These RDDs have the following characteristics:
- they are organized online: Be careful because these lines cannot exceed 2 GB. In practice, it is even advisable not to go beyond a few MB.
- It is almost impossible to access a part of the file precisely. It will therefore be necessary to browse it in its entirety because of course the RDDs do not have an index
- They work like streams or cursors (read or write): we cannot therefore modify an RDD !
- They are distributed. The order of the rows of the dataset is not known in advance (Corollary of this, it does not store the names of the columns).
So much for the big drawbacks, but thanks to the Pandas Bookstore , we’ll see how to overcome them easily.
NB: install PySpark via the command $ pip install pyspark
Spark & Python
Let’s say it: Spark is implemented in Java!
The PySpark API is quite efficient but will never be as efficient and efficient as the Java API (or scala). However, for most Machine Learning projects, PySpark will do just fine. And then you will see that it is rather easy to use.
Hadoop cluster
Hadoop side I will use for this tutorial the HortonWorks distribution (HDP 2.6.4).
You can download the sandbox here .
Once the cluster is installed and configured, you can access the AMBARI administration console via the URL: http://
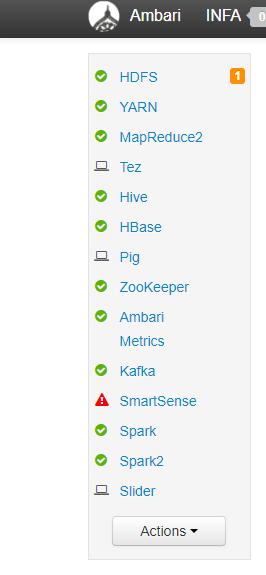
Log in as admin and verify that HDFS and HIVE services are operational:
Then retrieve the hive parameter. metastore. uris in the Ambari console. To do this, select Hive from the left menu, then the Configs and Advanced tabs in the right pane:
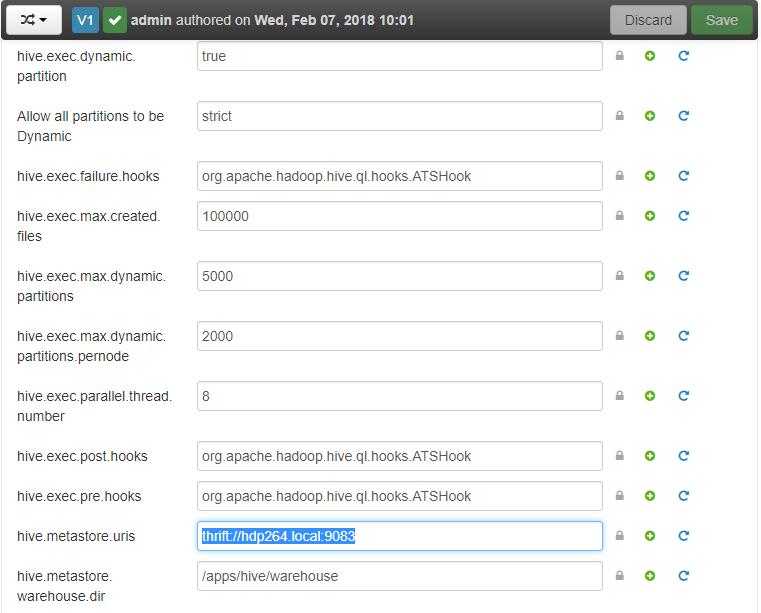
In my case I put aside the value: thrift://hdp264.local:9083
Hadoop HDFS
Let’s get to the heart of the matter and see how we are going to be able to write and read a file in a Hadoop HDFS cluster with Python.
Some useful commands
Interacting with HDFS is pretty straightforward from the command line. Here is a little memento:
List a directory:
$ hadoop fs -ls
Create a folder :
$ hadoop fs -mkdir /user/input
Change rights :
$ hadoop fs -chmod 777 /user
Send files :
$ hadoop fs -put /home/file.txt /user/input
Read file :
hadoop fs -cat /user/infa/Exp_Clients.csv
Get file :
hadoop fs -get /user/output/ /home/hadoop_tp/
Writing a file in HDFS with PySpark
You know how to interact with HDFS from the command line now, let’s see how to write a file with Python (PySpark). In the example below we will create an RDD with 4 rows and two columns (data) then write it to a file under HDFS (URI: hdfs: //hdp.local/user/hdfs/example.csv ):
import os
from pyspark.sql import SparkSession
import pandas as pd
os.environ["HADOOP_USER_NAME"] = "hdfs"
os.environ["PYTHON_VERSION"] = "3.5.6"
sparkSession = SparkSession.builder.appName("pyspark_test").getOrCreate()
data = [('data 1', 1), ('data 2', 2), ('data 3', 3), ('data 4', 4)]
df = sparkSession.createDataFrame(data)
df.write.csv("hdfs://hdp.local/user/hdfs/example.csv")
Let’s check that the file has been written correctly. To do this in the Ambari console, select the “Files View” (matrix icon at the top right). Navigate to / user / hdfs as below:
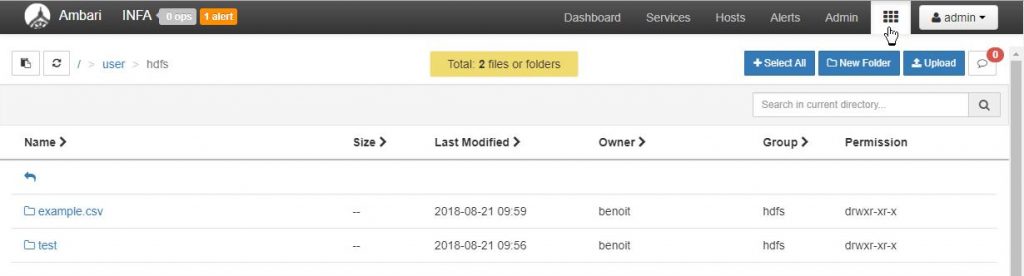
Good news the example.csv file is present
Playing a file in HDFS with PySpark
Reading is just as easy as writing with the sparkSession.read.csv command:
import os
from pyspark.sql import SparkSession
import pandas as pd
os.environ["HADOOP_USER_NAME"] = "hdfs"
os.environ["PYTHON_VERSION"] = "3.5.6"
sparkSession = SparkSession.builder.appName("pyspark_test").getOrCreate()
df = sparkSession.read.csv('hdfs://hdp.local/user/hdfs/example.csv')
df.show()
The show () method displays the contents of the file.
Hive
We have just seen how to write or read a file in HDFS. Now let’s see how we can interact with Hive with PySpark.
Some useful Hive commands
You run hive from the command line simply by typing $ hive. Once the hive client is operational, it offers a hive> prompt with which you can interact:
List all tables
hive> SHOW TABLES;
List all the tables ending with e (Cf. regular expressions):
hive> SHOW TABLES '.*e';
Description of a table (columns):
hive> DESCRIBE INFA.EMPLOYEE;
Database :
hive> CREATE DATABASE [IF NOT EXISTS] userdb;
hive>SHOW DATABASES;
hive>DROP DATABASE IF EXISTS userdb;
You can of course do HiveQL:
SELECT [ALL | DISTINCT] select_expr, select_expr, …
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[HAVING having_condition]
[CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list]] [LIMIT number];
hive> SELECT * FROM employee WHERE salary>30000;
“Request” Hive with PySpark
For that I created a customers_prov table in Hive that we are going to request. But first of all you will have to specify your Hive URI (ie the parameter hive. Metastore. Uris that you retrieved above). Replace the value “thrift: //hdp.local: 9083” in the code below with yours:
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession, HiveContext
import pandas as pd
SparkContext.setSystemProperty("hive.metastore.uris", "thrift://hdp.local:9083")
sparkSession = (SparkSession
.builder
.appName('pyspark_test')
.enableHiveSupport()
.getOrCreate())
df_spark = sparkSession.sql('select * from customers_prov')
df_spark.show()
Unfortunately RDDs are not very usable for my taste. Of course we will have some useful methods:
- df_spark.schema () which displays the schema
- df_spark.printSchema (): which displays the same diagram but in the form of a tree
- etc.
But personally I love the magic command that transforms these RDDs into DataFrame Pandas: toPandas ()
s = df_spark.toPandas()
And there you have it, you can design and work on your Machine Learning Model
Find the sources of this tutorial in Jupyter notebooks in GitHub



