The Stochastic Gradient Descent (SGD) & Learning Rate
 by
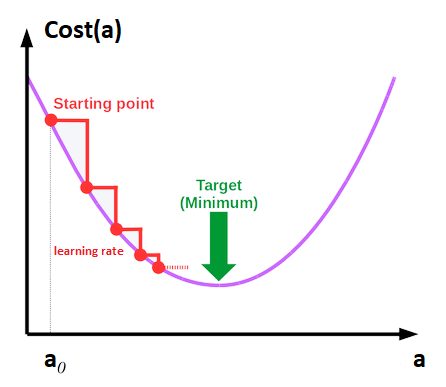
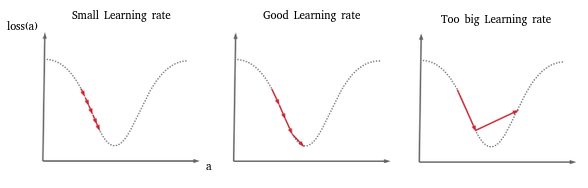
by When I finished the article on gradient descent, I realized that there were two important points missing. The first concerns the stochastic approach when we have too large data sets, the second being to see very concretely what happens when we poorly choose the value of the learning rate. I will therefore take advantage of this article to finally continue the previous article 😉