
 by
by To follow up on my article on the management of character strings, here is a first part which will allow us to have a progressive approach to the processing of this type of data. Far from any semantic approach (which will be the subject of a later post), we will discuss here the technique of bags of words. This technique, also called “bag of words” is a simple first approach and much more effective than it seems.
We will first see the general principles of this technique and then we will see how with scikit-learn (Python) we can set up a practical case and see its execution.
Index
The principle of the bag of words
In the end, the principle of the bag of words is quite simple. You can say that it even looks like the one-hot encoding that we saw in a previous article . Its principle can be summed up in 3 phases:
- The decomposition of words. This is also called tokenization.
- The constitution of a global dictionary which will in fact be the vocabulary.
- The encoding of the character strings in relation to the vocabulary formed previously.
Here is a block diagram
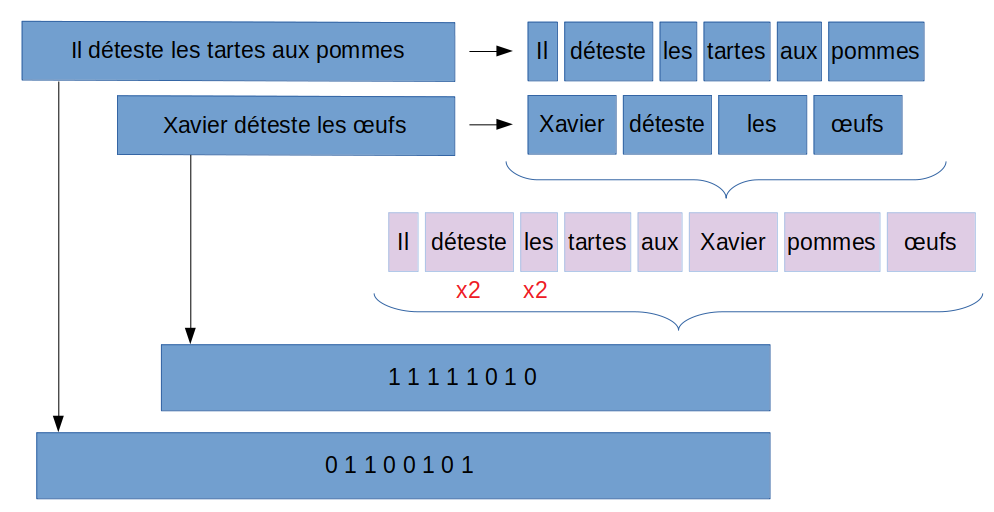
Tokenization
Tokenization is a simple but essential step. The principle is simple: you have to cut the sentence (s) into phonemes or words. Of course we immediately think of cutting with spaces, but we will not forget the punctuation elements either. Fortunately Scikit-Learn helps us in this step with its ready-to-use tokenization functions:
CountVectorizer() et TfidfVectorizer()
Vocabulary creation
It is obvious that we are not going to deal with a single sentence! we will have to process a large number of them, and therefore we are going to constitute a sort of dictionary (or vocabulary) which will consolidate all the words that we have tokenized. See diagram above.
This dictionary (vocabulary) will then allow us to perform the encoding necessary to “digitize” our sentences. In fact and to summarize, this step allows us to create our bag of words. At the end of this step, we will therefore have all the (unique) words that make up the sentences in our data set. Attention to each word will also be given an order, this order is very important for the encoding step which follows.
Encoding
This is the step that will transform our words into numbers. Once again the idea is simple, from a sentence in your dataset, you match the vocabulary previously formed. Be careful of course to resume the order established in the previous step!
So for each new sentence, it must be tokenized (same method as for the constitution of the vocabulary) and then confront each word. If the word of the sentence exists in the vocabulary, then it suffices to put a 1 for the location (order) of the word in the vocabulary.
Implementation with Scikit-Learn
For example we will take the data set that we had scraped here (video games).
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
T = pd.read_csv("../webscraping/meilleursjeuvideo.csv")
cv = CountVectorizer()
texts = T["Description"].fillna("NA")
cv.fit(texts)
The CountVectorizer () function is a magic function which will split (via regular expression) the sentence. Here we will create a vocabulary from the Description column and “tokenize” all the columns.
cv = CountVectorizer()
texts = T["Description"].fillna("NA")
cv.fit(texts)
print ("Taille: {}", len (cv.vocabulary_))
print ("Contenu: {}", cv.vocabulary_)
Here is the vocabulary automatically created by Scikit-Learn (we get it via vocabulary_):
Taille: {} 2976Contenu: {} {'dans': 681, 'ce': 435, 'nouvel': 1793, 'épisode': 2944, 'de': 688, 'god': 1197, 'of': 1827, 'war': 2874, 'le': 1480, 'héros': 1303, 'évoluera': 2970, 'un': 2755, 'monde': 1676, 'aux': 273, 'inspirations': 1357, 'nordiques': 1784, 'très': 2731, 'forestier': 1118, 'et': 1001, 'montagneux': 1683, 'beat': 332, 'them': 2654, 'all': 122, 'enfant': 938, 'accompagnera': 55, 'principal': 2080, 'pouvant': 2056, 'apprendre': 184, 'des': 710, 'actions': 71, 'du': 806, 'joueur': 1420, 'même': 1741, 'gagner': 1159, 'expérience': 1030, 'the': 2652, 'legend': 1486, 'zelda': 2903, 'breath': 381, 'wild': 2882, 'est': 1000, ..., 'apparaît': 177, 'tribu': 2715, 'wario': 2875, 'land': 1471, 'pyramide': 2157, 'peuplant': 1960}
You will notice that it is a list made up of words and numbers. These numbers are the encoding orders that we mentioned above, quite simply.
You will also notice that the vocabulary is made up of 2976 words. This means that the sentences that make up the Description column contain 2976 distinct words.
Now we have to create the representation of the data itself, for that we have to call the transform () function:
bow = cv.transform(texts)
print ("Sac de mots: {}", bow)
sdm = bow.toarray()
sdm.shape
print(sdm)
The result is a matrix (200, 2976) because we have 200 rows and 2976 new columns.
array([[0, 0, 0, ..., 0, 0, 0],
[0, 1, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 1],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]])
Limit vocabulary size
If you take a look at the vocabulary you will notice that a lot of the words are unnecessary. We are talking about link words or other numbers which will not really add any values thereafter. In addition, the number of columns with the word bag technique is likely to grow impressively, we must find a way to limit them.
A good method is therefore to remove unnecessary words from the vocabulary. For this we have at least 2 approaches:
- Limit vocabulary creation via the number of occurrences
- Use stop words
Limitation via the number of occurrences
By default when we created our vocabulary from datasets we added an entry when it appeared at least 2 times. We can simply increase this parameter which will have the effect of limiting the number of entries in the vocabulary and therefore giving more importance to words which are used several times.
With scikit-Learn just use the min_df parameter as follows:
cv = CountVectorizer(min_df=4).fit(texts)
print ("Taille: {}", len (cv.vocabulary_))
print ("Contenu: {}", cv.vocabulary_)
The size of the vocabulary then decreases considerably: Taille: {} 379
Stop Words
But what are Stop Words? Simply a list of explicit words to be removed from the vocabulary.
Scikit-Learn offers a predefined list of words in its API but unfortunately in English, for other languages you will have to create your own list.
Of course you can start from scratch and create your own excel file. You can also start from an existing list. For French, a good starting point is on the site https://www.ranks.nl/stopwords/french . You just have to copy this list via the site or why not also scrap it ! In short, I did it for you and do not hesitate to resume the list here (Github) .
Then nothing could be simpler,
stopwordFR = pd.read_csv("stopwords_FR.csv")
cv = CountVectorizer(min_df=4, stop_words=stopwordFR['MOT'].tolist()).fit(texts)
print ("Taille: {}", len (cv.vocabulary_))
print ("Contenu: {}", cv.vocabulary_)
The size decreases further: Taille: {} 321
There you go, now instead of sentences you have recovered digital data that is much more usable than textual information.



