 by
by NLPCloud.io is an API that makes it easy to use NLP in production. The API is based on the pre-trained models from spaCy and Hugging Face Transformers. You can also use your own spaCy models. NLPCloud.io supports the following features: entities extraction (NER), sentiment analysis, text classification, text summarization, question answering, and Part-of-speech (POS) tagging.
The API is available for free up to 3 requests per minute, which is a good way to easily test the quality of the models. Then the first paid plans costs $39 per month (for 15 requests per minute).
Let’s see how to use the API in this tutorial.
Index
Why NLPCloud.io ?
Deploying AI models to production is a frequent source of project failure. NLP models are very resource intensive, and ensuring high availability of these models in production, while having good response times, is a challenge. It takes and expensive infrastructure and advanced DevOps, programming, and AI skills.
NLP Cloud’s goal is to help companies quickly leverage their models in production, without any compromise on quality, and at affordable prices.
Create an Account
Sign Up
Sign up is very quick. Just visit https://nlpcloud.io/home/register and fill your email + password.
Retrieve an API Token
You are now in your dashboard and you can see your API token. Keep this token safely, you will need it for all the API calls you will make.
Documentation
Several code snippets are provided in your dashboard in order for you to quickly get up to speed. For more details, you can then read the documentation.
NLPCloud.io API Usage
NLP Cloud provides you, out-of-the-box, with most of the typical NLP features, either thanks to pre-trained spaCy or Hugging Face models, or by uploading your own spaCy models.
Client Libraries
In order to make the API easy to use, NLP Cloud provides you with client libraries in several languages (Python, Ruby, PHP, Go, Node.js). In the rest of this tutorial, we are going to use the Python lib.
Use PIP in order to install the Python lib:
pip install nlpcloud
Entities Extraction (NER)
Entities extraction is done via spaCy. All the spaCy “large” pre-trained models are available, which means that 15 languages are available (more details on all these models on the spaCy website). You can also upload custom in-house spaCy models that you developed by yourself in order to use them in production. If that’s what you want, just go to the “Custom Models” section in your dashboard:

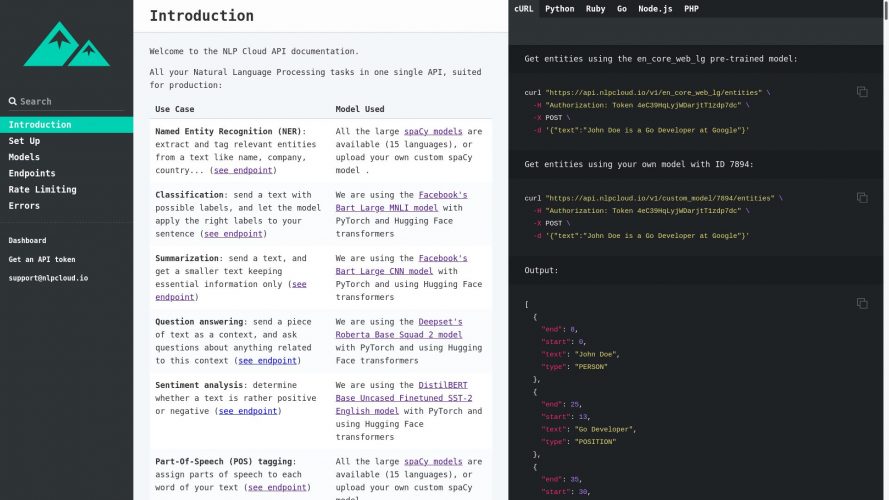
Now let’s imagine that you want to extract entities from the sentence “John Doe has been working for Microsoft in Seattle since 1999.” thanks to the pre-trained spaCy model for English (“en_core_web_lg”). Here’s how you should proceed:
import nlpcloud
client = nlpcloud.Client("en_core_web_lg", "<your API token>")
client.entities("John Doe has been working for Microsoft in Seattle since 1999.")
It will return the content of each extracted entity and its position in the sentence.
Sentiment Analysis
Sentiment analysis is achieved thanks to Hugging Face transformers and the Distilbert Base Uncased Finetuned SST 2 English model. Here’s an example:
import nlpcloud
client = nlpcloud.Client("distilbert-base-uncased-finetuned-sst-2-english", "<your API token>")
client.sentiment("NLP Cloud proposes an amazing service!")
It will tell you whether the general sentiment in this text is rather positive or negative, and its likelihood.
Text Classification
Text classification is achieved thanks to Hugging Face transformers and the Facebook Bart Large MNLI model. Here is an example :
import nlpcloud
client = nlpcloud.Client("bart-large-mnli", "<your API token>")
client.classification("""John Doe is a Go Developer at Google.
He has been working there for 10 years and has been
awarded employee of the year.""",
["job", "nature", "space"],
True)
As you can see, we are passing a block of text we are trying to classify, along with possible categories. The last argument is a boolean that defines whether one single category or several ones can apply.
It will return the likelihood for each category.
Text Summarization
Text summarization is achieved thanks to Hugging Face transformers and Facebook Bart Large CNN model. Here’s an example:
import nlpcloud
client = nlpcloud.Client("bart-large-cnn", "<your API token>")
client.summarization("""The tower is 324 metres (1,063 ft) tall,
about the same height as an 81-storey building, and the tallest structure in Paris.
Its base is square, measuring 125 metres (410 ft) on each side. During its construction,
the Eiffel Tower surpassed the Washington Monument to become the tallest man-made
structure in the world, a title it held for 41 years until the Chrysler Building
in New York City was finished in 1930. It was the first structure to reach a
height of 300 metres. Due to the addition of a broadcasting aerial at the top of
the tower in 1957, it is now taller than the Chrysler Building by 5.2 metres (17 ft).
Excluding transmitters, the Eiffel Tower is the second tallest free-standing structure
in France after the Millau Viaduct.")
It will return a summarization of the above. This is an “extractive” summary, and not an “abstractive” one, which means that no new sentence is generated. However non-essential sentences are removed of course.
Question Answering
Question answering is achieved thanks to Hugging Face transformers and Deepset Roberta Base Squad 2 model. Here’s an example:
import nlpcloud
client = nlpcloud.Client("roberta-base-squad2", "<your API token>")
client.question("""French president Emmanuel Macron said the country was at war
with an invisible, elusive enemy, and the measures were unprecedented,
but circumstances demanded them.""",
"Who is the French president?")
Here it’s about answering a question thanks to a context.
For example the above example will return “Emmanuel Macron”.
Part-of-Speech (POS) Tagging
POS tagging is achieved thanks to the same spaCy models as the one used for entities extraction. So for example if you want to use the English pre-trained model, here’s how you should do:
import nlpcloud
client = nlpcloud.Client("en_core_web_lg", "<your API token>")
client.dependencies("John Doe is a Go Developer at Google")
It will return the part-of-speech of each token in the sentence, and its dependency on other tokens.
Conclusion
NLPCloud.io is une API for NLP that is easy to use and that helps you save a lot of time in production.
The team plans to add new models, depending on demand (translation, text generation…).
Also note that, for critical performance needs, GPU plans are also proposed.
I hope this article was useful to some of you! If you have any question, please don’t hesitate to let me know.



