by
by Index
XGBoost principle
If you did not know this algorithm, now is the time to fix it because it is a real star of machine learning competitions . Simply put XGBoost (like eXtreme Gradient Boosting) is an optimized open source implementation of the gradient boosting trees algorithm.
But what is Gradient Boosting?
Gradient Boosting is a supervised learning algorithm whose principle is to combine the results of a set of data and weaker models in order to provide a better prediction.
This is also referred to as the model aggregation method. The idea is therefore simple: instead of using a single model, the algorithm will use several which will then be combined to obtain a single result.
It is above all a pragmatic approach which therefore makes it possible to manage both regression and classification problems.
To briefly describe the principle, the algorithm works sequentially. Unlike the Random Forest, for example. this way of doing things will make it slower, of course, but it will above all allow the algorithm to improve by capitalization compared to previous executions. He therefore begins by building a first model that he will of course evaluate (we are of course supervised learning). From this first evaluation, each individual will then be weighted according to the performance of the prediction. Etc.
XGBoost behaves remarkably in machine learning competitions ( Machine Learning ), but not only due to its principle of sequential self-improvement …
XGBoost indeed includes a large number of hyperparameters which can be modified and tuned for improvement!
This great flexibility therefore makes XGBoost a solid choice that you should definitely try.
XGBoost in practice
Other good (or bad) news: XGBoost is not part of Scikit-Learn… but integrates perfectly well with it. The examples below use this integration, but be aware that of course you can use XGBoost without having Scikit-Learn.
We will be recovering and working on our good old Titanic dataset . You remember ? it’s about predicting if a passenger will survive… so it’s a binary classification problem. So we will obviously use XGBoost as a classifier.
from xgboost import XGBClassifier
from sklearn.preprocessing import MinMaxScaler
import pandas as pd
import xgboost as xgb
train = pd.read_csv("../titanic/data/train.csv")
test = pd.read_csv("../titanic/data/test.csv")
Obviously we will not cut to a little data preparation, that is not the objective of this article so we will make it very simple here. Here is a small Python function that will prepare the training and testing games:
def dataprep(data):
sexe = pd.get_dummies(data['Sex'], prefix='sex')
cabin = pd.get_dummies(data['Cabin'].fillna('X').str[0], prefix='Cabin')
# Age
age = data['Age'].fillna(data['Age'].mean())
emb = pd.get_dummies(data['Embarked'], prefix='emb')
# Prix du billet / Attention une donnée de test n'a pas de Prix !
faresc = pd.DataFrame(MinMaxScaler().fit_transform(data[['Fare']].fillna(0)), columns = ['Prix'])
# Classe
pc = pd.DataFrame(MinMaxScaler().fit_transform(data[['Pclass']]), columns = ['Classe'])
dp = data[['SibSp']].join(pc).join(sexe).join(emb).join(faresc).join(cabin).join(age)
return dp
So let’s prepare these datasets and recover the labels for the training set:
Xtrain = dataprep(train)
Xtest = dataprep(test)
y = train.Survived
Now let’s train our XGBoost algorithm. For the hyper-parameters we will take the default ones.
boost = XGBClassifier()
boost.fit(Xtrain, y)
p_boost = boost.predict(Xtrain)
print ("Score Train -->", round(boost.score(Xtrain, y) *100,2), " %")
Hyper-Parameters
Of course, XGBoost is configurable, find the list of hyper-parameters on the site directly https://xgboost.readthedocs.io/en/latest/parameter.html
Be careful, you will have to manage these parameters on 3 levels:
- General settings
- The parameters of the chosen booster (these depend on the previous choices)
- The learning parameters (regression and classification will not have the same inputs here).
Here is an example of parameter assignment when instantiating the classifier:
param = {}
param['booster'] = 'gbtree'
param['objective'] = 'binary:logistic'
param["eval_metric"] = "error"
param['eta'] = 0.3
param['gamma'] = 0
param['max_depth'] = 6
param['min_child_weight']=1
param['max_delta_step'] = 0
param['subsample']= 1
param['colsample_bytree']=1
param['silent'] = 1
param['seed'] = 0
param['base_score'] = 0.5
clf = xgb.XGBClassifier(params)
Evaluation
In addition to the metrics that we discussed in the evaluation of classification algorithms , the XGBoost library provides some interesting metrics.
Graph showing the fields by degree of importance:
xgb.plot_importance(boost)
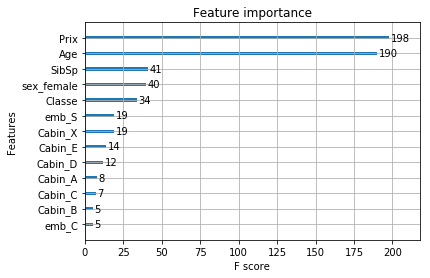
Graph showing the result:
xgb.to_graphviz(boost, num_trees=2)
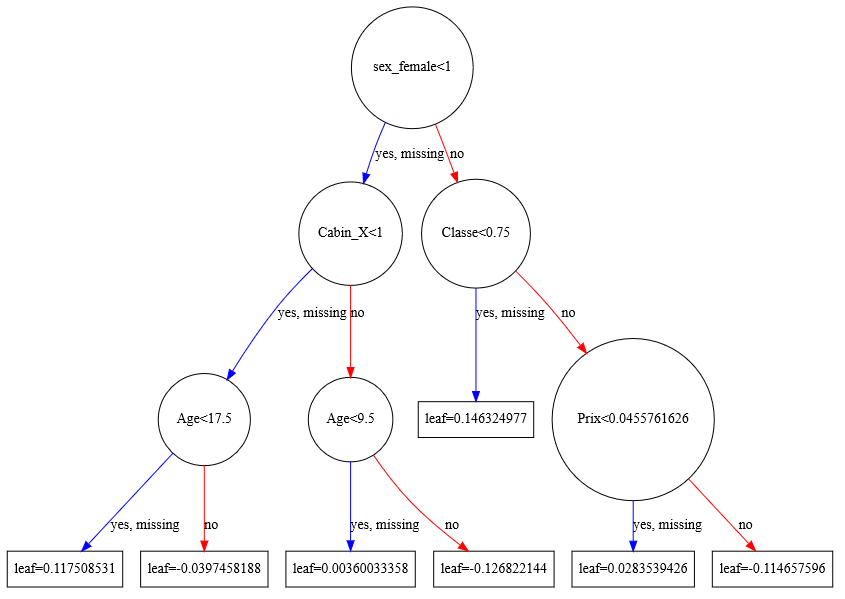
Save and load a model
The library also includes the possibility of saving and reloading a model:
Saving a trained model:
boost._Booster.save_model('titanic.xbmodel')
Loading a saved model:
boost = xgb.Booster({'nthread': 4}) boost.load_model('titanic.xbmodel')
And without Scikit-Learn?
As I said above we can quite use XGBoost independently of Scikit-Learn, here are the few differences:
import xgboost as xgb
dtrain = xgb.DMatrix(x_train,y_train)
param = {'boost':'linear',
'learnin_rate':0.1,
'max_depth': 5,
'objective': 'reg:linear',
'eval_metric':'rmse'}
num_round = 100
bst = xgb.train(param, train, num_round)
preds = bst.predict(dtest)
Warning!
As for the other algorithms based on trees… beware of overfitting (on learning). For that we will come back to the good old recipes: limit the size of trees (no pun intended) but also to build and work on samples from the initial data set.
In the same family of gradient boosting algorithms, I also invite you to read my article on CatBoost .