
 by
by What do a Convolutional Neural Network, NLP, and Fake News have in common?
Nothing ? well I can already see one: this article 🙂
Jokes aside in this post we’ll create a convolutional neural network (CNN) to do some NLP stuff, and for the data I would base myself on a dataset that you can simply find in the Kaggle datasets: FrenchFakeNewsDetector (published by Gilles Hachemes ). You have understood the objective is twofold: on the one hand to see how we can use the convolution technique with vectors (1 dimension instead of images with 2+ dimensions) and on the other hand to do NLP with data in French.
Index
Get dataset from Kaggle
As I said in the introduction we are going to draw from a dataset published in kaggle. By the way you will also find the notebook with the code for this article in Kaggle here.
Note: The dataset is very simple and not too big, however I advise you if you are using Google Colaboratory or Kaggle Notebook to activate the GPUs otherwise the training phase will be quite slow.
This dataset is composed of 3 columns:
- Column 1: media (we won’t use it)
- Column 2: the text which contains a news (true or false ???)
- Column 3: the label which specifies whether the news is true (0) or false (1)
About the volume we only have 9494 (training and testing) which should be sufficient for a binary classification with a CNN.
Note: If you are not using Kaggle Notebook you will however have to download the training and test datasets manually.
Environment preparation
To perform this binary classification (fake news or not?) We will use:
- Python bien sur
- NLTK (NLP)
- TensorFlow 2.x (CNN)
- sklearn
Here are the needed Python imports:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import re
import string
import nltk
from nltk.corpus import stopwords
from nltk import word_tokenize
from nltk.stem.snowball import FrenchStemmer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report,confusion_matrix
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.layers import Dense, Input, GlobalMaxPooling1D
from tensorflow.keras.layers import Conv1D, MaxPooling1D, Embedding
from tensorflow.keras.models import Model
from tensorflow.keras.callbacks import EarlyStopping
Regarding NLTK, the datasets in French must be imported explicitly (for tokenization and stopwords):
nltk.download('stopwords')
nltk.download('punkt')
[nltk_data] Downloading package stopwords to /root/nltk_data...
[nltk_data] Unzipping corpora/stopwords.zip.
[nltk_data] Downloading package punkt to /root/nltk_data...
[nltk_data] Unzipping tokenizers/punkt.zip.
TrueDataset
First of all, you have to retrieve and read the two datasets in order to put them in a Pandas DataFrame:
dataset_train = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/frfakenews/datafake_train.csv',delimiter=';', encoding='utf-8')
dataset_test = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/frfakenews/datafake_test.csv',delimiter=';', encoding='utf-8')
Note: for this example I am using Google colab and I downloaded and then imported both datasets into my Google Drive.
I don’t like column names too much and we also need to remove the first column:
def reformatDataset(df):
df = df.drop(["media"], axis=1)
df = df.rename(columns={'fake': 'label', 'post': 'text'})
return df
dataset_train = reformatDataset(dataset_train)
dataset_test = reformatDataset(dataset_test)
Text Preparation
Removing punctuation
As the punctuation elements are of no interest to our model, we are going to remove them. We will also remove the numbers and carriage return characters at the same time:
def remove_punct(_str):
_str = re.sub('['+string.punctuation+']', ' ', _str)
_str = re.sub('[\r]', ' ', _str)
_str = re.sub('[\n]', ' ', _str)
_str = re.sub('[«»…"]', ' ', _str)
_str = re.sub('[0-9]', ' ', _str)
return _str
And what does that looks like ?
print("Before ->", dataset_train['text'][5])
print("After ->", remove_punct(dataset_train['text'][5]))
Before -> Notre-Dame-des-Landes : « La décision prise par l’exécutif est la moins risquée pour lui » 53.Cédric Pietralunga, journaliste au service politique du « Monde », a répondu aux questions des internautes après l’annonce de l’abandon du projet d’aéroport à Notre-Dame-des-Landes..partage facebook twitter
After -> Notre Dame des Landes La décision prise par l’exécutif est la moins risquée pour lui Cédric Pietralunga journaliste au service politique du Monde a répondu aux questions des internautes après l’annonce de l’abandon du projet d’aéroport à Notre Dame des Landes partage facebook twitterNot bad, let’s apply this function for both datasets:
dataset_train['text'] = dataset_train['text'].apply(remove_punct)
dataset_test['text'] = dataset_test['text'].apply(remove_punct)
Remove unnecessary words (stop-words)
For this we will use NLTK (and more particularly the words in French that we downloaded previously):
french_stopwords = set(stopwords.words('french'))
filtre_stopfr = lambda text: [token for token in text if token.lower() not in french_stopwords]
We can now create a function that removes these words but also tokenizes and removes words with less than 3 letters:
# Tokenize, remove stop words and remove the little words (less than 3 characters)
def remove_stop_words_fr(_str):
return [ txt for txt in filtre_stopfr(word_tokenize(_str)) if len(txt)>2]
dataset_train['text'] = dataset_train['text'].apply(remove_stop_words_fr)
dataset_test['text'] = dataset_test['text'].apply(remove_stop_words_fr)
Preparing the dataset for Tensorflow
Let’s prepare the vectors (1 dimension) that we will pass to CNN:
tokenizer = Tokenizer(num_words=50000, lower=None)
tokenizer.fit_on_texts(dataset_train['text'])
seq_train = tokenizer.texts_to_sequences(dataset_train['text'])
seq_test = tokenizer.texts_to_sequences(dataset_test['text'])
Print some infos here :
print("Nb of texts: " , tokenizer.document_count)
#print("Word indexes: " , tokenizer.word_index)
print("Word/token counts: " , len(tokenizer.word_counts))
nb_token = len(tokenizer.word_index)
Nb of texts: 6645
Word/token counts: 48712We have almost 50,000 tokens to process in our matrix.
We complete the vectors to have the same dimensions. For this we “complete” the test set (padding):
ds_train = pad_sequences(seq_train)
train_seq_len = ds_train.shape[1]
ds_test = pad_sequences(seq_test, maxlen=train_seq_len)
We create to finish the labels (test and training):
y_train = dataset_train['label'].astype('int')
y_test = dataset_test['label'].astype('int')
Modeling the convolutional neural network (CNN)
Our network is made up of several layers:
- Input
- Embedding
- 1 convolution layer (32 filters)
- 1 pooling layer
- 1 convolutional layer (64 filters)
- 1 pooling layer
- 1 convolution layer (128 filters)
- 1 Max pooling layer (1 dimensional vector)
- 1 Dense (classic) layer with sigmoid activation because we are doing a binary classification.
mon_cnn = tf.keras.Sequential()
mon_cnn.add(Input(shape=(train_seq_len,)))
mon_cnn.add(Embedding(nb_token + 1, 120))
mon_cnn.add(Conv1D(32, 3, activation='relu'))
mon_cnn.add(MaxPooling1D(3))
mon_cnn.add(Conv1D(64, 3, activation='relu'))
mon_cnn.add(MaxPooling1D(3))
mon_cnn.add(Conv1D(128, 3, activation='relu'))
mon_cnn.add(GlobalMaxPooling1D())
mon_cnn.add(Dense(1, activation='sigmoid'))
We are dealing with a binary classification problem (fake news or not). We compile the CNN with the binary_crossentropy function:
mon_cnn.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
mon_cnn.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 4031, 120) 5845560
_________________________________________________________________
conv1d (Conv1D) (None, 4029, 32) 11552
_________________________________________________________________
max_pooling1d (MaxPooling1D) (None, 1343, 32) 0
_________________________________________________________________
conv1d_1 (Conv1D) (None, 1341, 64) 6208
_________________________________________________________________
max_pooling1d_1 (MaxPooling1 (None, 447, 64) 0
_________________________________________________________________
conv1d_2 (Conv1D) (None, 445, 128) 24704
_________________________________________________________________
global_max_pooling1d (Global (None, 128) 0
_________________________________________________________________
dense (Dense) (None, 1) 129
=================================================================
Total params: 5,888,153
Trainable params: 5,888,153
Non-trainable params: 0Fit the model
We will now train our model.
But first of all let’s define an early-stopping function with a patience of 2 which means that the training will stop as soon as the loss (on the test set) increases twice in succession. This allows us to avoid doing too many iterations (epochs) but also and above all to limit over-training (over-fitting):
early_stop = EarlyStopping(monitor='val_loss', patience=2)
mon_cnn.fit(x=ds_train,
y=y_train,
validation_data=(ds_test, y_test),
epochs=30
,callbacks=[early_stop]
)
Epoch 1/30
208/208 [==============================] - 60s 145ms/step - loss: 0.4455 - accuracy: 0.7627 - val_loss: 0.0816 - val_accuracy: 0.9758
Epoch 2/30
208/208 [==============================] - 28s 136ms/step - loss: 0.0331 - accuracy: 0.9886 - val_loss: 0.0831 - val_accuracy: 0.9716
Epoch 3/30
208/208 [==============================] - 28s 135ms/step - loss: 0.0038 - accuracy: 0.9991 - val_loss: 0.0931 - val_accuracy: 0.9677
<tensorflow.python.keras.callbacks.History at 0x7fe0fdbc2610>3 epochs only and rather good scores on the test game (accuracy: 97%)
Evaluation
Let’s look at the loss and precision graphs (by epochs):
losses = pd.DataFrame(mon_cnn.history.history)
losses[['accuracy', 'val_accuracy']].plot()

And for the accuracy …
losses[['loss', 'val_loss']].plot()
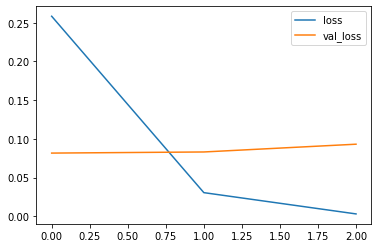
Let’s take a look at the precision and recall:
from sklearn.metrics import precision_score, recall_score
y_test_pred = np.where(mon_cnn.predict(ds_test) > .5, 1, 0).reshape(1, -1)[0]
print("Precision: {:.2f}%".format(100 * precision_score(y_test, y_test_pred)))
print("Recall: {:.2f}%".format(100 * recall_score(y_test, y_test_pred)))
Precision: 96.53%
Recall: 96.95%We have a good balance here …


