
 by
by When analyzing data, it is important (especially if you are doing machine learning) to detect if your variables (features) are related. In some cases it is obvious (like for example the dependency link in a hierarchy) but very often these links or correlations are almost invisible. We will therefore have to detect and measure these potential links. fortunately tools and techniques exist, let’s go through them together.
Index
A little theory
To use Wikipedia’s definition which I find rather well found:
“In probability and statistics, the correlation between several random or statistical variables is a notion of connection which contradicts their independence. ”
The objective will therefore consist in measuring the strength of the link that there is between two (or more) variables. However, this link can be more or less complex. We think first of all of a linear type link… and by extension we will quickly turn to linear regression to find this link.
Linear relationship
Naturally, therefore, we will evaluate the linear relation between two continuous variables: it is the Pearson correlation.
The graphs below show Pearson’s coefficients (r) which show a positive (r> 0), negative (r <0) or no correlation (r = 0) correlation:
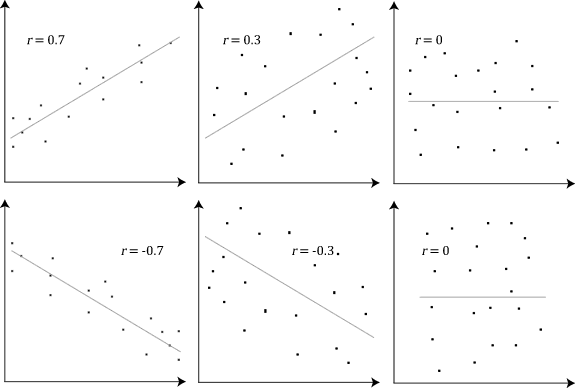
Non-linear relationship
Unfortunately all the dependency relations are not necessarily linear, and therefore we will have to push the regressions further (polynomial, etc.). We will therefore turn to the Spearman correlation (rho) which evaluates the monotonic relation between two variables. In a monotonic relationship, the variables tend to change together, but not necessarily at a steady rate.
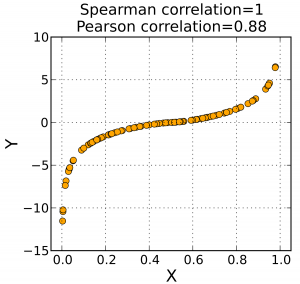
Let’s go back to Wikipedia’s definition once again :
We study Spearman’s correlation when two statistical variables seem to be correlated without the relationship between the two variables being of affine type . It consists in finding a correlation coefficient, not between the values taken by the two variables but between the ranks of these values. She estimates how much the relationship between two variables can be described by a monotonic function .
A final measurement ( Kendall’s Tau ) allows us to measure the association between two variables. More specifically, Kendall’s tau measures the rank correlation between two variables.
Some differences anyway in these two measures (used in practice for nonlinear correlations):
- Kendall’s Tau : Returns values generally lower than Spearman’s rho correlation. Calculations are based on matching and discordant pairs. This method is immune to error. The values are more accurate with smaller samples.
- Spearman’s Rho : Gives values that are generally greater than Kendall’s Tau. The calculations are based on the deviations. it is much more sensitive to errors and discrepancies in the data (outliers).
A little practice with Orange
With Orange , nothing could be simpler! Use the Correlation widget (Data group), and connect it to a data source as below. You will be able to consult in a few clicks the coefficients of Pearson and Spearman (and not Kendall):
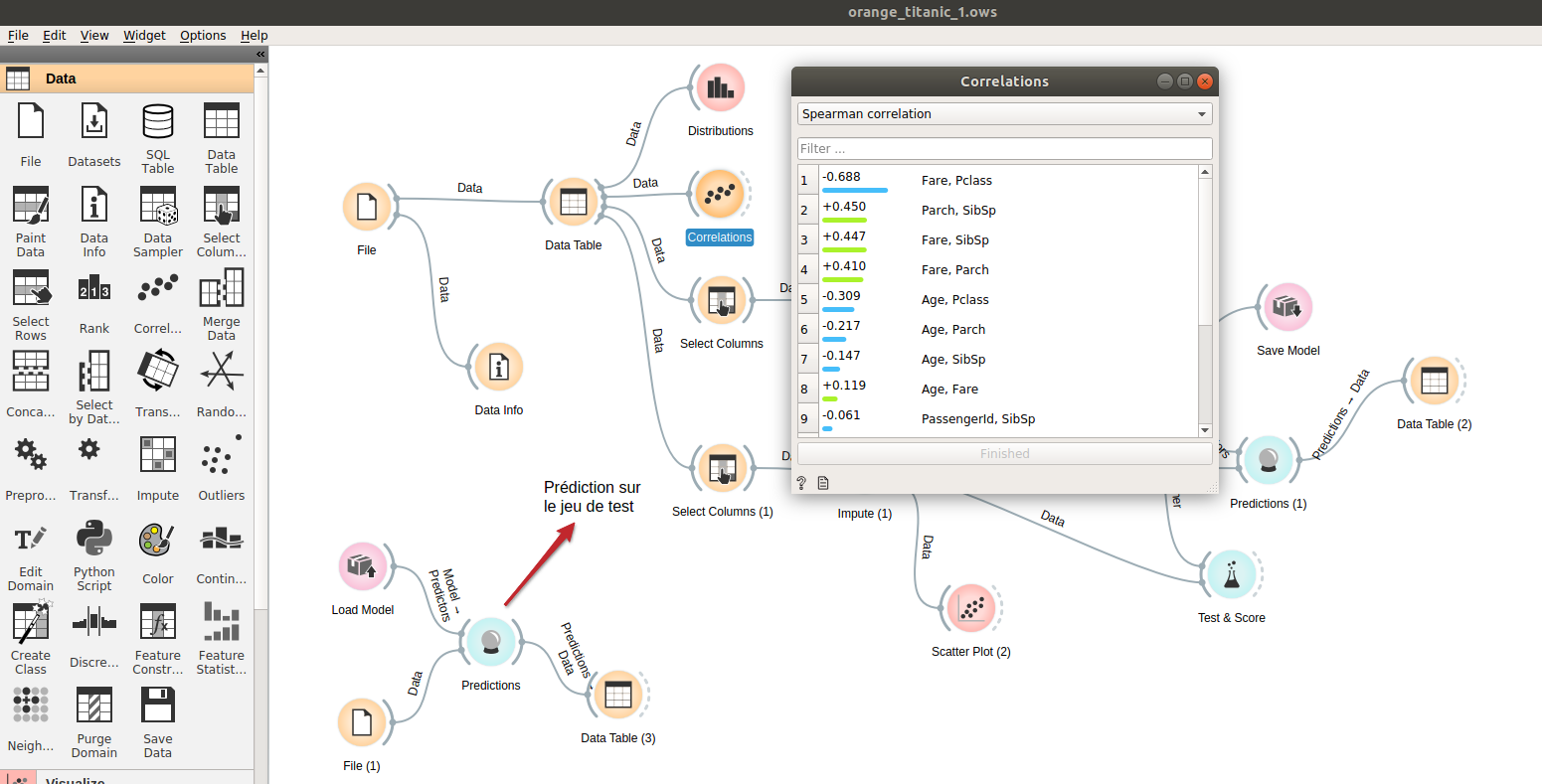
And with Python!
Using Python it is hardly more complex because the calculation of these coefficients is included in the Pandas library .
Let’s take a simple example:
import pandas as pd
import numpy as np
from matplotlib import pyplot
k = pd.DataFrame()
k['X'] = np.arange(5)+3
k['Y'] = [1, 3, 4, 8, 12]
pyplot.scatter(k['X'], k['Y'], s = 150, c = 'red', marker = '*', edgecolors = 'blue')
Let’s see the distribution with matplotlib :

A simple call to the corr () method of the Dataframe object provides you with the correlation matrix between these two variables:
k.corr(method='pearson')
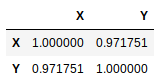
To request another type of coefficient (Spearman, Kendall, or custom), just change the method parameter as follows:
k.corr(method='spearman')
k.corr(method='kendall')
To calculate the correlations on a set of columns, it is not more complicated, it is enough to pass all the DataFrame
titanic = pd.read_csv("../datasources/titanic/train.csv")
data = titanic.drop(['Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1)
data.corr(method='spearman')
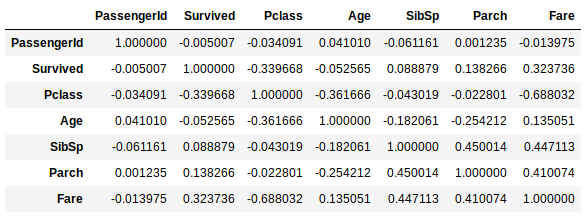
With a heatmap grid, this will make the result more visible and interpretable:
data.corr(method='spearman').style.format("{:.2}").background_gradient(cmap=pyplot.get_cmap('coolwarm'))
# Cf. https://matplotlib.org/examples/color/colormaps_reference.html pour les codes couleurs
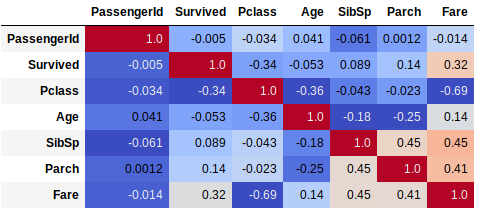
Now you know what you have to do as soon as you enter the analysis phase of your data. As usual, the source codes are available on Github .


