
 by
by Index
Service purpose
In order to put into practice what we have seen in the previous articles, I suggest you create a web service (RESTFul) in Python which will retrieve an image (invoice scan) to process it and return the constituent elements. So as not to start too complex (and maybe also because I don’t have enough input data) we will process the content of invoices without Machine Learning (I’m not talking about OCR of course).

Here are the different processing steps:
- Image recovery (JPEG) in binary form by the REST Web Service. We will use Flask .
- Image analysis with OCR. We will be using Tesseract which we saw in a previous article .
- Retrieving invoice elements and creating a JSON file.
- Return of the response (JSON content).
Technical prerequisite:
- Python (I’m using version 3.7 here). you will also need the libraries (pytesseract, opencv, flask, json)
- Tesseract (with the pytesseract library)
Analysis of the invoice image
The invoice analysis (which is provided in the form of a JPEG file) is carried out via Tesseract .
Here is the invoice template that we will analyze ( you can also download it on my github):
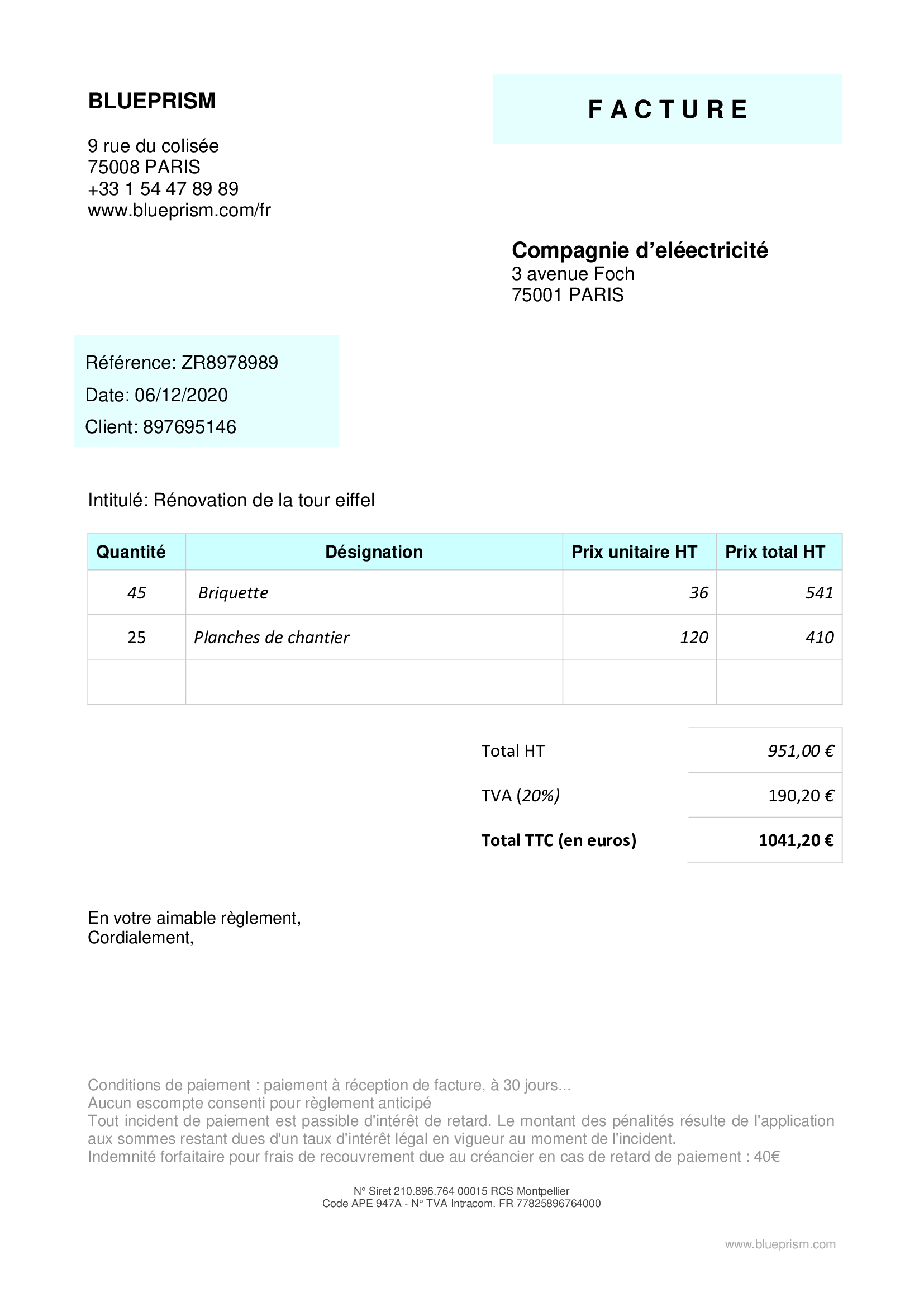
For that we must import the python libraries first and then initialize Tesseract as follows:
try:
from PIL import Image
except ImportError:
import Image
import pytesseract
import json
import cv2
import numpy as np
# Si votre installation de Tesseract n'est pas dans le path ou si l'exécutable ne se nomme pas exactement tesseract, joutez les lignes suivantes :
#pytesseract.pytesseract.tesseract_cmd = r'tesseract-4.0.0.exe'
#fichier = r'/home/monuser/git/python_tutos/tesseract/tessFactures/Facture_1.jpg'
fichier = r'Facture_2.jpg'
image = Image.open(fichier)
print(pytesseract.image_to_string(image))
Normally you should have as a result (this is the literal transcription of the image … basically this is how tesseract understood the JPEG file):
BLUEPRISM FACTURE
9 rue du colisée
75008 PARIS
+33 1 54 47 89 89
www.blueprism.com/fr
Compagnie d’eléectricité
3 avenue Foch
75001 PARIS
Référence: ZR8978989
Date: 06/12/2020
Client: 897695146
Intitulé: Rénovation de la tour eiffel
Quantité Désignation Prix unitaire HT — Prix total HT
45 Briquette 36 541
25 Planches de chantier 120 410
Total HT 951,00 €
TVA (20%) 190,20 €
Total TTC (en euros) 1041,20€
En votre aimable réglement,
Cordialement,
Conditions de paiement : paiement a réception de facture, a 30 jours...
Aucun escompte consenti pour reglement anticipé
Tout incident de paiement est passible d'intérét de retard. Le montant des pénalités résulte de l'application
aux sommes restant dues d'un taux d'intérét legal en vigueur au moment de I'incident.
Indemnité forfaitaire pour frais de recouvrement due au créancier en cas de retard de paiement : 40€
N° Siret 210.896.764 00015 RCS Montpellier
Code APE 947A - N° TVA Intracom. FR 77825896764000Retrieving items from the invoice
We will use the invoice markers to retrieve the various elements that interest us: address, name, amounts, invoice elements, total, etc.
As I said in the preamble we could (if we had enough data / invoices) to use Machine learning algorithms for this step, but to start we will do simple things, starting from the assumption that we are always dealing with the same types of invoices here. (from the same supplier).
First of all, I’m going to create some functions that will allow you to collect all the elements in a generic way:
def RemoveEmptyLines(entree):
tab = entree.strip()
tableausansvide = [ x for x in tab.splitlines() if x!='' ]
res = ''
for i in range(0, len(tableausansvide)):
res = res + tableausansvide[i] + '\n'
return res
def getTextBetween(mainString, startWord, endWord):
start = mainString.find(startWord) + len(startWord)
end = mainString.find(endWord)
return RemoveEmptyLines(mainString[start:end])
def getPosElement(po):
element = {}
element['quantite'] = po[0:po.find (' ')].strip()
po = po[po.find (' '):len(po)]
element['prixtotht'] = po[po.rfind (' '):len(po)].strip()
po = po[0:po.rfind (' ')]
element['prixunitht'] = po[po.rfind (' '):len(po)].strip()
po = po[0:po.rfind (' ')]
element['decription'] = po.strip()
return element
Then one by one we will retrieve each element of the invoice and place them in a JSON object. The json objects in python are managed with a disconcerting ease, it is enough to affect the variables directly and the json library manages all the syntax by adding the {} and [] to it as necessary.
output = {}
resultat = pytesseract.image_to_string(image)
output["Adresse"] = getTextBetween(resultat, 'www.blueprism.com/fr', 'Référence').strip()
output["Reference"] = getTextBetween(resultat, 'Référence: ', 'Date: ').strip()
output["DateFacture"] = getTextBetween(resultat, 'Date: ', 'Client: ').strip()
output["CodeClient"] = getTextBetween(resultat, 'Client: ', 'Intitulé: ').strip()
# Récupération des lignes de PO
pos = getTextBetween(resultat, 'Prix total HT', 'Total HT ')
tabPOs = pos.splitlines()
print ('Nombre de PO: ' + str(len(tabPOs)))
output["NbPo"] = len(tabPOs)
pos = []
for i in range(0, len(tabPOs)):
pos.append(getPosElement(tabPOs[i]))
output['po'] = pos
output["totalht"] = getTextBetween(resultat, 'Total HT ', 'TVA (20%) ').strip()
output["tva"] = getTextBetween(resultat, 'TVA (20%) ', 'Total TTC (en euros) ').strip()
output["total"] = getTextBetween(resultat, 'Total TTC (en euros) ', 'En votre aimable réglement,').strip()
The json (output) object is therefore created from the invoice, let’s look at the result:
print (output)
{'Adresse': 'Compagnie des eaux\n2 rue de la foret\n45879 BOIS VILLIERS', 'CodeClient': '98908908', 'DateFacture': '12/12/2020', 'NbPo': 1, 'Reference': 'ZR980980', 'po': [{'decription': "tomette — Réf 'Toscane blanc' (20*20)", 'prixtotht': '276', 'prixunitht': '23', 'quantite': '12'}], 'total': '331,20 €', 'totalht': '276,00 €', 'tva': '55,20€'}REST service build
Now we are going to make this accessible via a web service call. For this we will use Flask with the particularity that we will send the image in binary format to the service to retrieve the previous json content. Let’s create a python file (file.py) which will contain the code of the service.
Let’s add the main road to it and specify the POST mode.
@app.route('/facture', methods=['POST'])
Then let’s get the binary stream of the image (sent in POST):
r = request
# convert string of image data to uint8
nparr = np.frombuffer(r.data, np.uint8)
# decode image
image = cv2.imdecode(nparr, cv2.IMREAD_COLOR)
Do not forget the encoding at the end of the processing to return a correct json stream:
# Prepare respsonse, encode JSON to return
response_pickled = jsonpickle.encode(output)
return Response(response=response_pickled, status=200, mimetype="application/json")
This is what it should look like:
from flask import Flask, request, Response
try:
from PIL import Image
except ImportError:
import Image
import pytesseract
import json
import jsonpickle
import numpy as np
import cv2
app = Flask(__name__)
# fonctions ici ...
@app.route('/')
def index():
return "Lecture de fichier de factures"
@app.route('/facture', methods=['POST'])
def order():
r = request
# convert string of image data to uint8
nparr = np.frombuffer(r.data, np.uint8)
# decode image
image = cv2.imdecode(nparr, cv2.IMREAD_COLOR)
output = {}
# ...
# Preprare respsonse, encode JSON to return
response_pickled = jsonpickle.encode(output)
return Response(response=response_pickled, status=200, mimetype="application/json")
if __name__ == '__main__':
app.run(debug=True, host='127.0.0.1', port=8080)
Vous pouvez télécharger le code complet sur Github.
Testons notre service
To test the service I advise you to use a Jupyter Notebook. Type the following code:
import requests
import json
import cv2
addr = 'http://localhost:8080'
url = addr + '/facture'
# prepare headers for http request
headers = {'content-type': 'image/jpeg'}
fichier = r'/home/benoit/git/python_tutos/tesseract/tessFactures/Facture_1.jpg'
img = cv2.imread(fichier)
# encode image as jpeg
_, img_encoded = cv2.imencode('.jpg', img)
Then start the flask service via a terminal / console. You should have something that looks like this if your flask server is launching well:
(base) benoit@benoit-laptop:~/git/python_tutos/tesseract/tessFactures$ python tessfacturews2.py
* Serving Flask app "tessfacturews2" (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: on
* Running on http://127.0.0.1:8080/ (Press CTRL+C to quit)
* Restarting with stat
* Debugger is active!
* Debugger PIN: 176-379-994
* Detected change in '/home/benoit/git/python_tutos/tesseract/tessFactures/tessfacturews2.py', reloading
* Restarting with stat
* Debugger is active!
* Debugger PIN: 176-379-994
Now let’s test our service by sending it the image:
# send http request with image and receive response
response = requests.post(url, data=img_encoded.tostring(), headers=headers)
# decode response
print(json.loads(response.text))
If all goes well you must recover:
{'Adresse': 'Compagnie des eaux\n2 rue de la foret\n45879 BOIS VILLIERS', 'CodeClient': '98908908', 'DateFacture': '12/12/2020', 'NbPo': 1, 'Reference': 'ZR980980', 'po': [{'decription': "tomette — Réf 'Toscane blanc' (20*20)", 'prixtotht': '276', 'prixunitht': '23', 'quantite': '12'}], 'total': '331,20 €', 'totalht': '276,00 €', 'tva': '55,20€'}What does it look like with a pdf file?
This is common when dealing with invoices. We can just as easily recover pdf files instead of scanned images. In this case, it is necessary to manage in addition to the difference in format the notion of pagination which does not exist in an image.
Regarding the processing of pdf, of course I want to talk about the pdf -> image conversion, I refer you to the article on advanced tesseract . Regarding we are going to create a new route for our web service in Flask in order to process our pdf file:
@app.route('/pdf', methods=['POST'])
def pdf():
r = request.data
output = {}
pytesseract.pytesseract.tesseract_cmd = r'tesseract-4.0.0.exe'
content = convert_from_bytes(r)
pages = []
output['Nb Pages'] = len(content)
print ("Nombre de pages: " + str(len(content)))
for i in range(len(content)):
pages.append(pytesseract.image_to_string(content[i]))
output['Pages'] = pages
# Preprare response, encode JSON to return
response_pickled = jsonpickle.encode(output)
return Response(response=response_pickled, status=200, mimetype="application/json")
And here it is, you can now send pdf files which will be processed by tesseract. the result being returned as a JSON file (in which you will find a Pages array with the content of each page).
Do not hesitate to test other invoices, I put 3 on github. Besides, you will find as usual all the code and files necessary to download on GitHub (git / les-tutos-datacorner.fr / computer-vision / tessFactures directory).



