
 by
by If you are using anaconda you have probably seen an Orange icon in Anaconda Navigator. If not, maybe you have done some research in DataScience tools and you stumbled upon this little free software that is Orange . In any case, I’ve wanted to try it out for a long time to see if this Open-Source tool could prove useful. So I started with the titanic data to see how to use it.
Index
Installer Orange
Install Orange
Even if you are using Anaconda, this software is not installed by default. On the other hand, a simple click on the Install button in the Anaconda Navigator will do it quite simply in a few seconds. Install the latest major version (version 3). Of course you can also do it from the command line:
conda config --add channels conda-forge
conda install orange3
You can also install it directly with pip:
pip install orange3
Discover the Orange environment
At first glance the environment seems simple. It breaks down into two parts:
- The widget palette (on the left): each widget will allow you to perform operations on the data
- A canvas (on the right) in which you will arrange your widgets and chain them.

The philosophy of Orange is quite simple and I would gladly compare it to Jupyter Notebook in the way it is used!
… With the difference that the first will allow you to design graphically while the second requires knowledge of Python! So no code with Orange and a totally graphical approach in which we link widgets point to point between them.
There are several categories of widgets in the palette:
- Data : to connect to data sources, analyze and perform operations on them.
- Visualize : to better see the data through graphs (bars, scatter plots, etc.)
- Model : To model and manage the persistence of your models.
- Evaluate : To predict and qualify your models.
- Unsupervised : for unsupervised modeling
- Etc.
Other groups of widgets are of course available through Orange Addons (Cf. Options menu). Be careful if you are on Windows some addons require Visual C ++ installed on your machine.
First manipulations
To add a widget, simply drag and drop it from the palette to the canvas. To connect two widgets between them you have to grab the right parenthesis of the first widget (source) and drag’n drop to the left parenthesis of the second (destination):
Tip: you can also (from the only source widget) do a drag’n drop in the void and let go. In this case a drop-down list of possible widgets to use will be proposed.
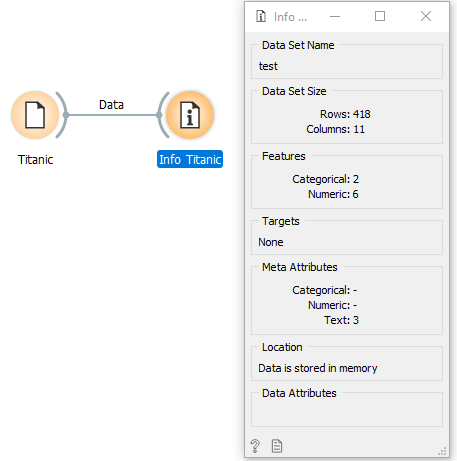
To see the result of a widget just double click on it. In the above case, this is what happens when I double-click on Info Titanic (Data Info widget):
Model the survival of the Titanic travelers
Did you understand how Orange works? alright so let’s take the Kaggle data from the Titanic and do our first model with this tool. Of course we will respect the 6 different phases of this type of project … but with Orange as our only companion!
First of all, you should know that Orange allows you to view data in Data Table objects (widgets) :
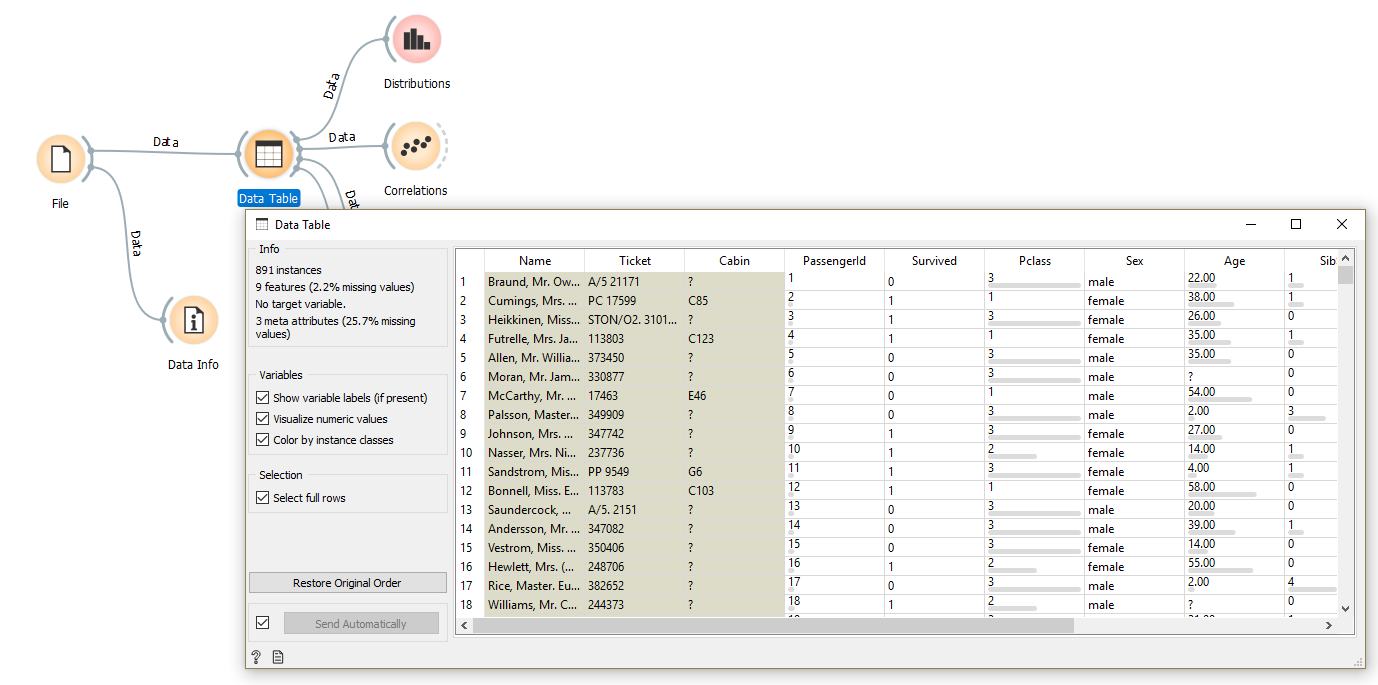
In order to analyze your data in relation to the result (here surviving or not) nothing like the analysis via the Distributions widget . This interactive widget will allow you to see your data on all facets:
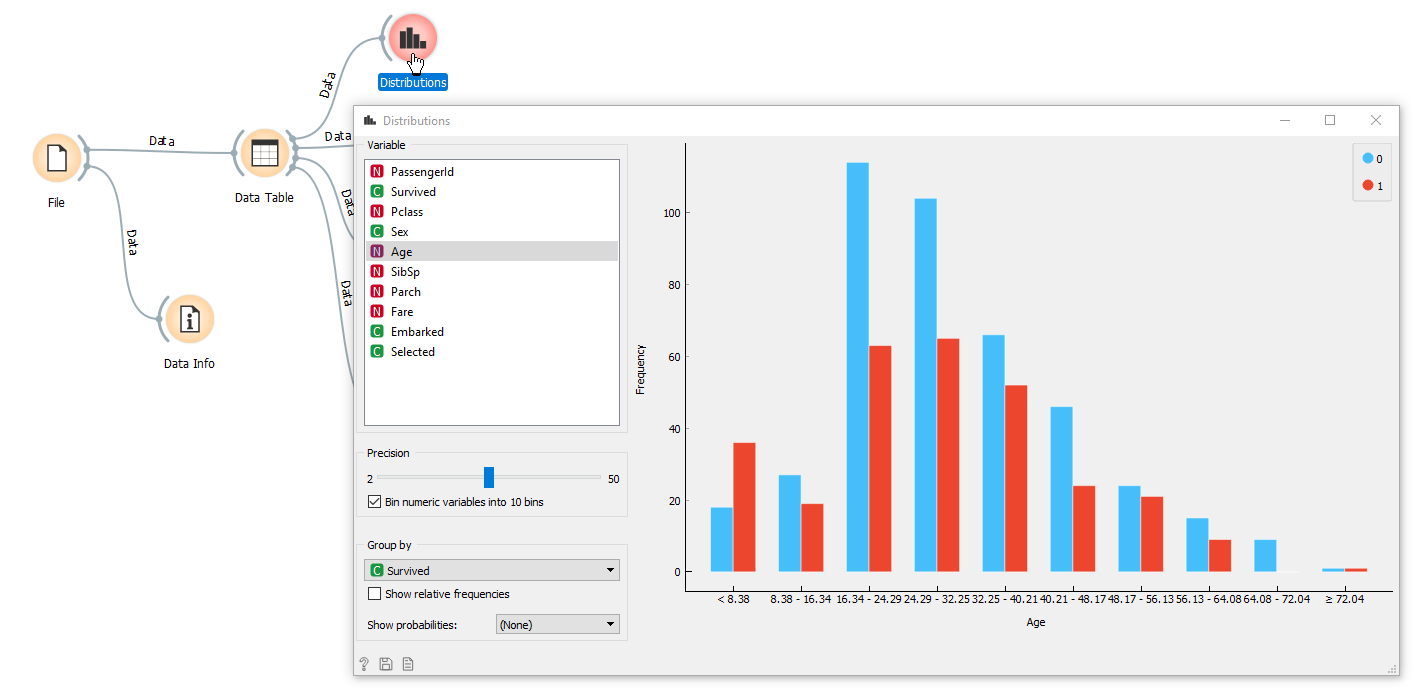
You will undoubtedly then see some correlations visually that you will be able to qualify via the Corellation widget :
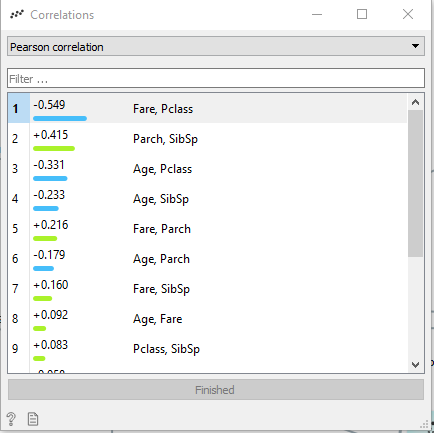
Hmmm! here we can see that there is for example a potential link between the cost of the ticket and the class!
Then we will chain together several widgets in order to train a model (decision tree). Here is the result :
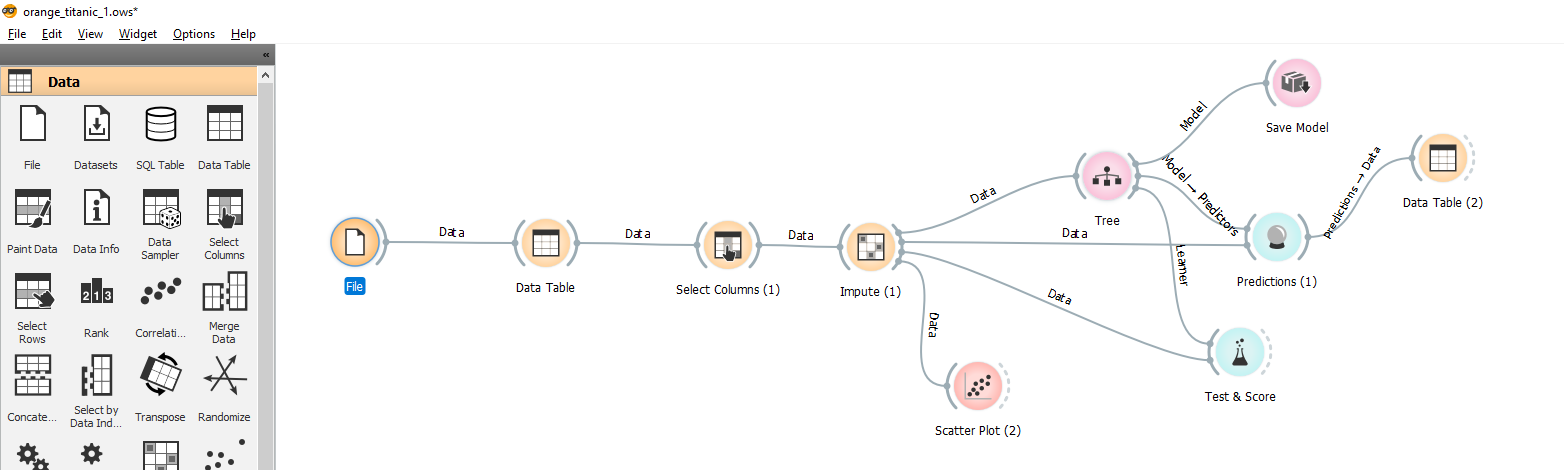
Some explanations are in order …
- File> Data Table : this is just a matter of offering the user to view the data.
- Data Table> Select Column : this widget allows you to create your work area (select and position the variables). Here you select the variables that you will take into account and specify (in the case of a supervised model) which column is the target:
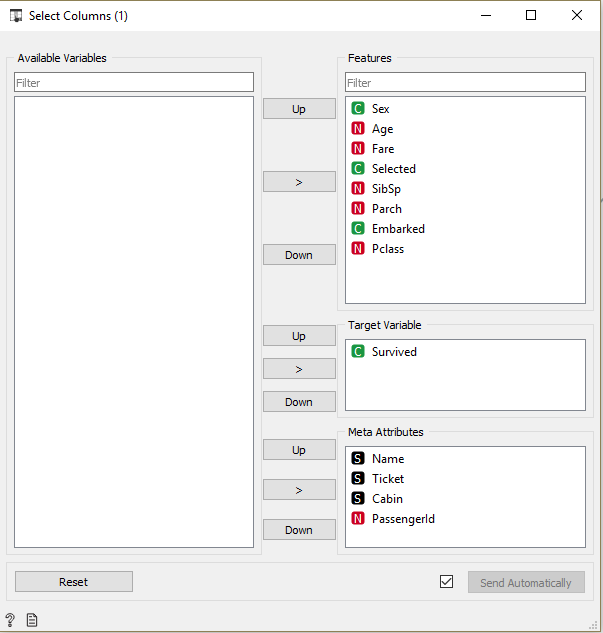
- Select Column > Impute : This widget allows you to easily manage the missing values of your data set and by variable / column:
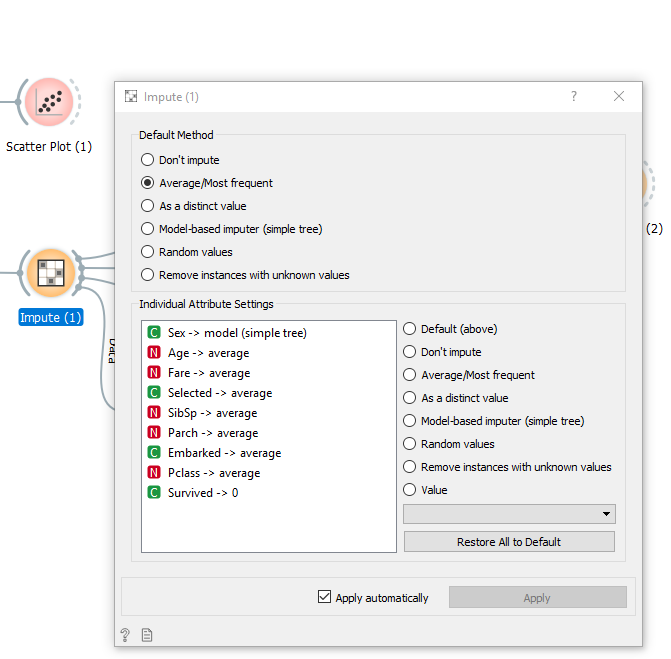
- Impute > Scatter plot : Allows you to interactively view the distribution of data:
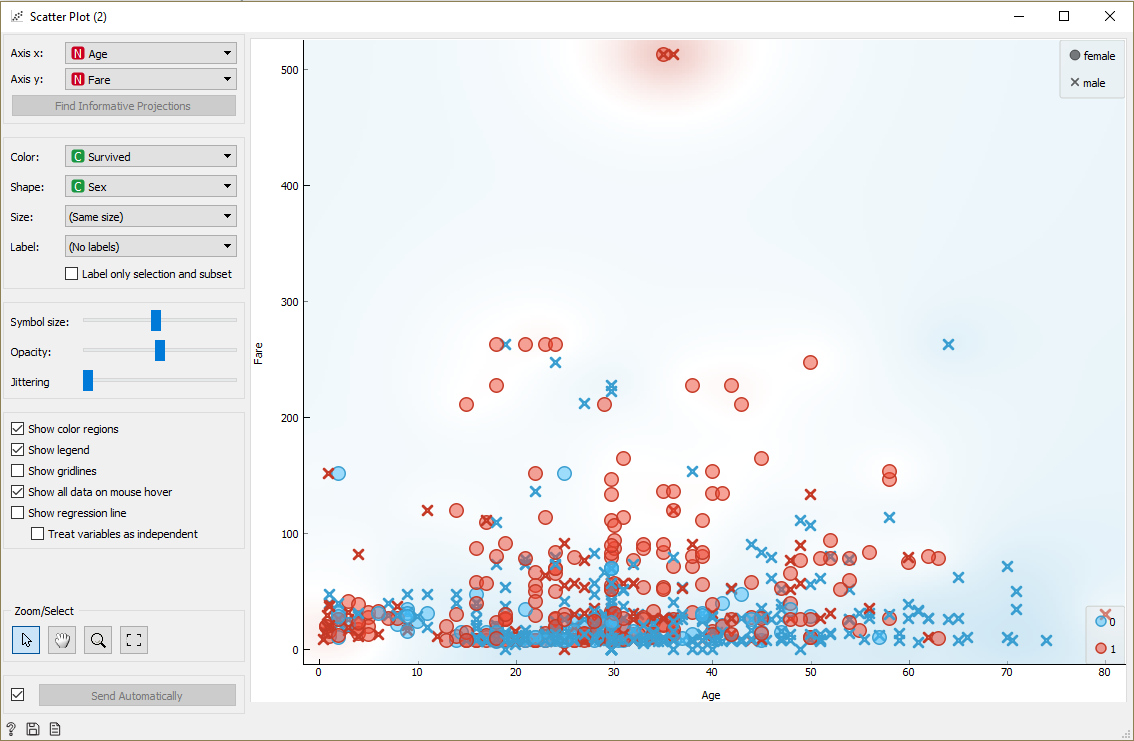
- Impute > Tree : Allows you to apply a decision tree algorithm to your dataset. You can specify the hyper-parameters here.
- Tree> Test & Score : This widget will give you your score (AUC, F1, and others in this case here)
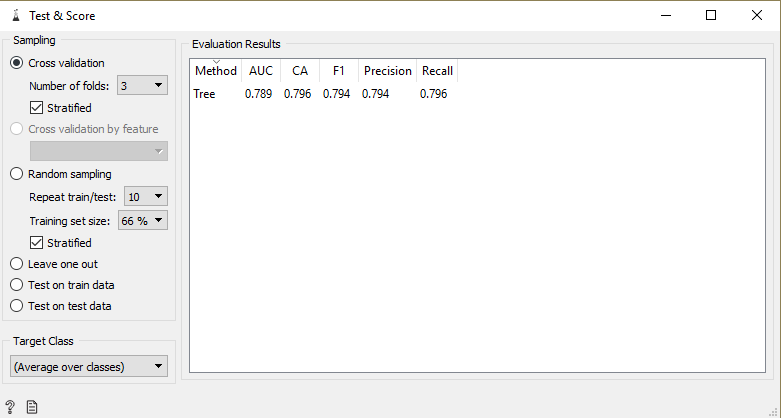
- Test & Score > Save Model : To save your trained model!
Use the template
Using a saved model is not very complex. To do this, you just have to use the Load Model widgets (with the file saved beforehand, see below), then the Predictions widget as follows:
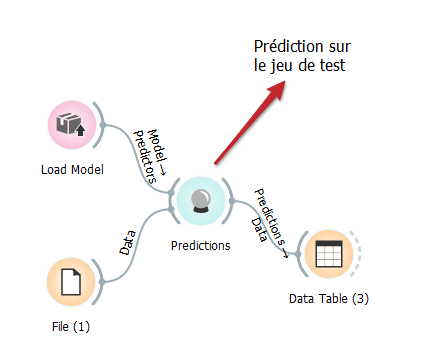
A video … (sorry but labels are in french)
Conclusion
Orange is a rather easy tool to learn. Nevertheless and by its approach, it can seem complex for those who are not used to Machine Learning projects (to these I suggest reading my article on the stages of this type of project here). In fact I find that it is a really very practical tool for prototyping but which finds certain limitations as soon as we have complex transformations (data preparation) to carry out or quite simply a lot of data preparation to carry out. Indeed the canvas becomes quickly then quickly unreadable … when you should not use the Python widget to code directly! Limitations therefore on the preparation part but a very good surprise on the other hand on the data visualization side (which turns out to be well suited toMachine Learning ).
The good news comes from the addons that extend the possibilities of the tool. It’s a new feature (2019), so the library is still quite poor. We can trust the community to quickly enrich it 🙂
The ergonomics are fluid and rather intuitive, even if from time to time we can get lost a bit on a few details (for example the management of links between widgets). Nothing really embarrassing anyway!
To conclude, I would say that Orange is a very fun tool that allows you to tackle and manage all the facets of a Machine Learning project . So it’s a good surprise… free in addition, so it’s a must-try tool!



U provide basic tust workflow, but the “devil” is hidden in details. (how do u prepare test dataset to predict new data in detail) Have base dataset matrix with named columns and rows. Trained model on that data set. I want to predict new column based on that dataset pattern (1 to n columns + new column in test-train-validate-forecast workflow all together). Basically i want to use NN’s to recognize and predict pattern based on old dataset. Its not time series ! What i can achieve is to predict already known data, and not new ones. I have tried to ad new column marked wit “?” like in WEKA but that doesn’t work in Orange. It predicts last known columns all the time no matter what i try. Predicting already known data is good only for testing of probability accuracy of trained model. So how do i enforce prediction of new column ?
Is that even possible with Orange ? No tutorial and no Orange doc covers that !? (prove me wrong, i have search all over the net). Seems to me i have to use some commercial software not to have such headaches.