
 by
by Index
What is Web Scraping?
If we refer to Wikipedia, Web Scrapping “allows you to recover the content of a web page in order to reuse the content”. In other words, Web Scrapping consists in recovering data from the web via the content of html pages. This is especially useful when you have surfed the internet and found the information you were looking for. But ouch! how to retrieve this information if the site does not publish them (in the form of API or CSV export).
Not everyone is or has the vocation to be “Open Data”!

For the literature aspects just know that we are talking about Web Scrapping but also – and it is the same thing – data harvesting.
If you take a look around the web you will find several tools (free or not, Open Source or not) that can also help you quickly. I will quote for example:
- OctoParse: https://www.octoparse.com/
- ParseHub: https://www.parsehub.com/
- Contentgrabber: https://contentgrabber.com/
- Mozenda: https://www.mozenda.com/
- etc.
In this article we will see how to retrieve data published on a website and then we will write it in a usable way – that is, in tabular form – in a csv file. Obviously we will not use any tool … that would be too simple
Your mission if you accept it
Your target will be the jeuvideo.com site. And more particularly the list of the best video games: http://www.jeuxvideo.com/meilleurs/

The idea is therefore just as simple, to retrieve the list of the best video games (the 200 best for example) and to write this list in a CSV file.
We will of course recover at a minimum:
- the name of the video game
- its description
- its release date
- his test score
- his player rating
Simple implementation with Python
As I said above, there are several tools that could do this automatically for you but I chose to show you how to do it with Python. You will see that it is really very simple and totally accessible.

To start, of course you have to go to the page you want to scrape and see if you find a structure in terms of CSS styles. Obviously if you do not know the style sheets this step will be difficult … but not impossible because with modern browsers you will have help
Retrieving the CSS style structure
In my example I am using Firefox. So just select the part you want to recover and right click on it. Finally choose “Examine the element” to display the content of the HTML page. A new panel should appear below with this famous HTML content (Cf. image below). You will see in this panel a highlighted line indicating the HTML code corresponding to the zone you had selected:
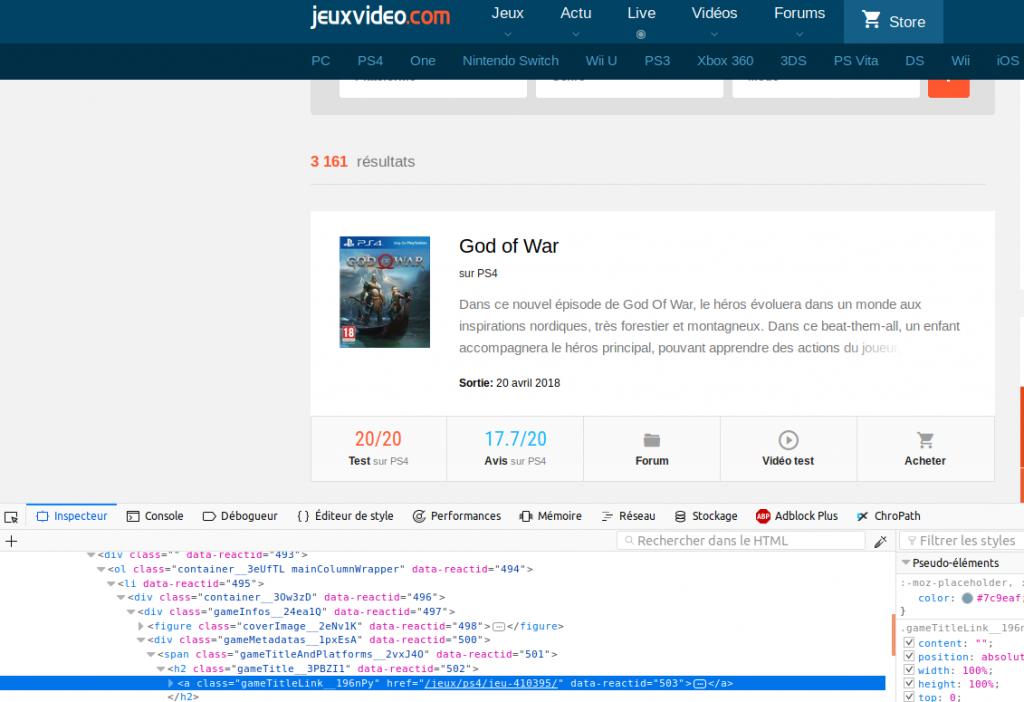
In our example we have selected the game title (God Of War). And we see that it is a hyperlink (tag A) which has CSS class gameTitleLink__196nPy. Very well we keep that under the elbow for later, and we will thereby recover the other desired information (description, notes, output).
Why are we getting the CSS classes? and quite simply because they will allow us to point via the Python code directly on the wanted elements thanks to the XPATH query language . In our example above for example the title (well all the titles) is found via the path XPATH: // a [@ class = “gameTitleLink__196nPy”]

Let’s scrap!
We now have the information necessary to retrieve the list of the best video games according to the site jeuvideo.com. Let’s start by opening a Jupyter notebook to code the scraping in Python.
import requests
import lxml.html as lh
page = requests.get('http://www.jeuxvideo.com/meilleurs/')
doc = lh.fromstring(page.content)
The code above retrieves the content of the page http://www.jeuxvideo.com/meilleurs/
nomJeux = doc.xpath('//a[@class="gameTitleLink__196nPy"]')
desc = doc.xpath('//p[@class="description__1-Pqha"]')
sortie = doc.xpath('//span[@class="releaseDate__1RvUmc"]')
test = doc.xpath('//span[@class="editorialRating__1tYu_r"]')
avis = doc.xpath('//span[@class="userRating__1y96su"]')
for i in range(len(nomJeux)):
print(nomJeux[i].text_content().strip() + "\n" + \
desc[i].text_content().strip() + "\n" + \
sortie[i].text_content().strip()+ "\n" + \
test[i].text_content().strip() + "\n" + \
avis[i].text_content().strip() + "\n")
Then we will retrieve the areas pointed to by the XPATH references and display them. And here it is magic, isn’t it?
Magic but not so exploitable in fact, I therefore suggest that you put this data in a Pandas DataFrame . To do this, we will create a function which will retrieve the data (via XPATH) and will create a DataFrame which takes a piece of data pointed by column and we will thereby have a set per row with all this information:
def getPage(url):
page = requests.get(url)
doc = lh.fromstring(page.content)
# Get the Web data via XPath
content = []
for i in range(len(tags)):
content.append(doc.xpath(tags[i]))
# Gather the data into a Pandas DataFrame array
df_liste = []
for j in range(len(tags)):
tmp = pd.DataFrame([content[j][i].text_content().strip() for i in range(len(content[i]))], columns=[cols[j]])
tmp['key'] = tmp.index
df_liste.append(tmp)
# Build the unique Dataframe with one tag (xpath) content per column
liste = df_liste[0]
for j in range(len(tags)-1):
liste = liste.join(df_liste[j+1], on='key', how='left', lsuffix='_l', rsuffix='_r')
liste['key'] = liste.index
del liste['key_l']
del liste['key_r']
return liste
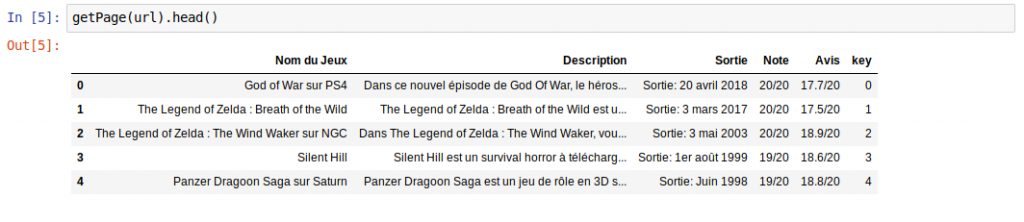
Here is the result:
What about pagination?
You will have noticed that we only collected the 20 best video games. This is quite logical given that the jeuvideo.com site displays data per page of 20! If we want to retrieve more information we will have to manage the automatic pagination of this site. To put it simply, we will have to wrap up on the HTTP criterion which makes it possible to manage this pagination, namely http://www.jeuxvideo.com/meilleurs/?p=X in order to have page X.
Here is the function that will allow you to loop to retrieve the _nbPages x 20 best video games:
def getPages(_nbPages, _url):
liste_finale = pd.DataFrame()
for i in range (_nbPages):
liste = getPage(_url + uri_pages + str(i+1))
liste_finale = pd.concat([liste_finale, liste], ignore_index=True)
return liste_finale
liste_totale = getPages(nbPages, url)
To finish you just have to save your data for example in a csv file:
liste_totale.to_csv('meilleursjeuvideo.csv', index=False)
The idea of this article was to show you that scraping can be a very simple task (as it is very complex in fact) and that above all this technique could be very useful to recover data that is necessarily made available.



One thought on “The Web Scraping”