
 by
by Index
Language
In the previous article we quickly discussed the training aspects (MOOC). the idea now is on the one hand to complete this section with a reading set but also and above all to equip oneself in order to be able to equip oneself and especially to practice. As I told you my approach will be above all experimental, we will tackle the theoretical part then. We are lucky, the subject is becoming more and more mature and now we have ready-made libraries available that allow you to get started without even having any mathematical knowledge.
Obviously these mathematical aspects (linear algebra, statistics and probabilities) are essential but can quite come in a second time in order to allow a better choice or more simply the refinement of the models used.
That being said, we must first of all choose the means and for that two possibilities are actually available to us. The Data Scientist, if he can choose the language of his choice in absolute terms, very quickly uses either the Python language or the R. The Python language is clearly the trend and is particularly well endowed in terms of libraries adapted to this profession. The R language being more available to statisticians … well anyway, it will probably and it seems to be used at one time or another.
So I would use the Python language.
Of course you will find plethora of tutorials on this language on the net, here are my favorite links
- The official website (US)
- A good little quick and efficient site on learning the Python language (FR)
- Developpez.com (FR)
- Tutorialspoint (US)
The distribution
We quickly realize that the strength of this language is not necessarily the language itself but especially the bookstores that are added to it. Numpy, pandas, flask, etc. are now part of the daily life of the Python developer, and that also means that these libraries must be managed … hence the choice of a distribution!
Only one choice is needed Anaconda!
To learn more about Anaconda simply go to the official website . What is more, it is a free distribution that is very easy to install and which in addition is cross-platform
On the other hand, it will be necessary to manage the environments. Indeed in order to use all the power of the libraries provided by Python (notably scikit-learn … although apparently at the time of writing this is not certain) you have to use version 2.7 of Python! however the latest version is 3.6. Good news, Anaconda manages the multi-environment very well. Here are the steps to create and switch to 2.7:
- First of all open the Anaconda navigator (it’s easier, even if you can do everything from the command line). If you are like me on Linux type in command line:
$ anaconda-navigator - Then go to the Environments menu, click on the Create icon below the middle list (see screen below).
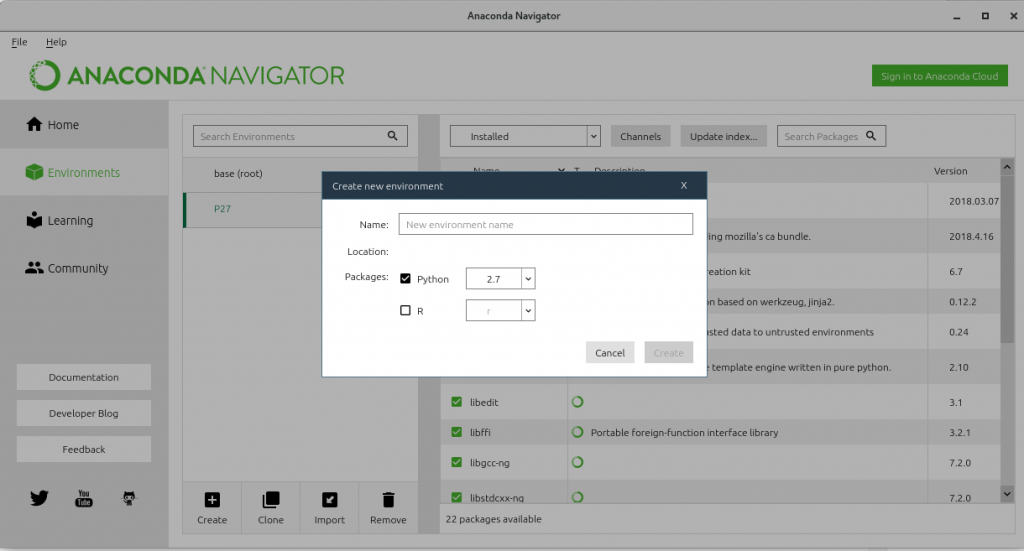
- Simply choose the version of Python to use, i.e. 2.7. Enter a name for your new environment, and you’re almost done.
- Now you have to select your default environment (the one you just created). For that, simply type in command line:
$ source activate P27
For convenience, here’s the link that explains how to manage Anaconda command line environments: https://conda.io/docs/user-guide/tasks/manage-environments.html#activating-an-environment
Regarding the IDE (especially for debugging purposes) I will recommend two approaches:
- For a traditional development type approach (with breakpoints, etc.): Eclipse + PyDev and Spyder are perfect (Spyder is also included with Anaconda) .
- For a “data” approach it is clear that jupyter is really practical. Certainly a little confusing at first (but not for long ), on the other hand very practical once you have it in hand.
Tip: I cannot update Anaconda once installed in graphics mode … to remedy this, type in command line:
For distribution:
$ conda update -n base conda
For Anaconda Navigator
$ conda update anaconda-navigator
The library
I was going to forget the books! Here are a few :
- FR – Machine Learning with Scikit-Learn (2017 Dunod)
- FR – DataScience by practice (Fundamentals with Python) (Eyrolles)
- FR – Machine Learning, From theory to practice – Fundamental concepts in Machine Learning (Eyrolles)
- FR – Data science – fundamentals and case studies – Machine learning with Python and R (Eyrolles 2015)
- US – Python Cookbook (O’Reilly 2005)
- US – Python in a nutshell (OReilly 2006)
- US – Python for Data Analysis. Data Wrangling with Pandas, NumPy, and IPython (2017, O’Reilly)
- US – SciPy and NumPy (O’Reilly)
- US – NumPy Beginners Guide (2015 O’Reilly)
Personally, I really appreciated the first one because it tackles data science in a practical and experimental way… But of course each has their own tastes.


